Creating A Compiler Part 2 - How Does A Compiler Work?
Compilers vs Interpreters
A compiler and interpreter’s job is to convert human readable source code into something a computer can execute. One friend of mine compared interpreters and compilers by using a book and a translator.
A compiler would read the book in one language, taking notes about key points in the book then translating the book into another language. Finally giving the whole translated book to someone else to read.
An interpreter would read the book in a language and after every sentence they verbally recite that translated sentence to someone else. Repeating these steps for the whole book.
An interpreter would stay with you the whole time, whereas a compiler will not.
Personally I do not like interpreted languages, mostly because of their dynamic typing which is often a hinderance than an actual good feature (I’m looking at you python!) Just implement type inference and keep variable declarations the same. Even Typescript can’t solve Javascripts problem entirely.
For interpreters and compilers, actually making sense of the source code given to them is mostly the same. It’s how they transform that data where the distinction is given.
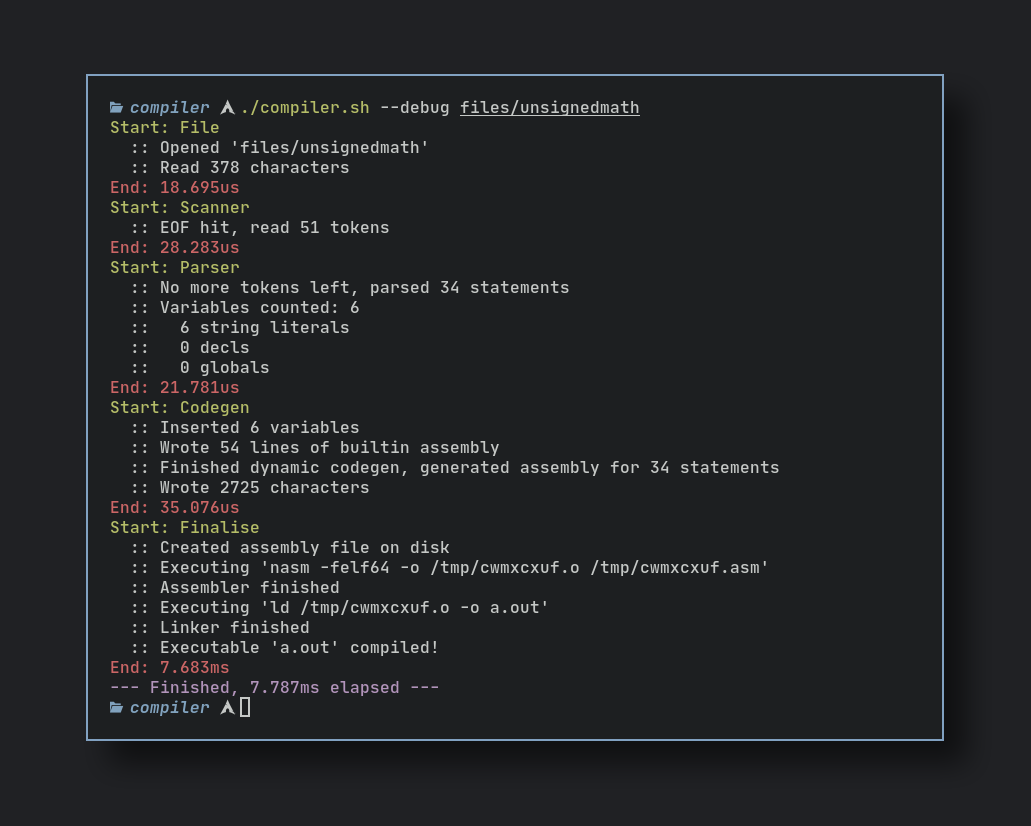
How my compiler makes sense of source code
Most compilers work like a pipeline, transforming input and feeding it into the next part in the sequence. My compiler is one of the simplest, it is currently comprised of three parts.
- Scanner/Lexer (Lexical analysis)
- Parser (Syntax analysis)
- Code generation
The Scanner
Computers don’t think like we do. They have no concept of words or numbers in text, strings in quotes mean nothing to them. Humans can look at this code:
declare hello_var "Hello!"
… and our brains will see it as such:
declare variable `hello_var` with string data "Hello!"
It’s because we’ve been trained to interpret things like grammar, context and words. Computers aren’t as literate as us, you need to give them rules to follow. Rules like matching all “declare” words to mean a “declare token” and all text inside single or double quotes are a “literal string token”. This is called lexical analysis and it’s already a solved problem.
I talked about the word “token” in the last sentence, it’s a way for a compilers to transform raw text into a format that contains a lot more metadata. Tokens usually encapsulate a “word” in the language, more about this below.
This is the token datatype used in my compiler:
struct Token {
pos int // position in source file
len int // length of token
row int // row in source file
col int // column in source file
lit string // literal representation
mut:
token Tok // token type for quick comparisons (enum)
}
… matching against these types:
enum Tok {
name
string_lit // "abc"
number_lit // 0123456789
inc // +
dec // -
add // +=
sub // -=
mul // *=
div // /=
mod // %=
divmod // %%
// --- keywords
declare
global
push
pop
drop
print
println
uput
uputln
}
Take this source file below:
| |
After stopping the compiler right after the scanning step, this is the token data it outputted. Exactly 9 tokens. Try to match parts of the source code with the individual tokens below:
1. 2. 3.
Token{ | Token{ | Token{
pos: 0 | pos: 7 | pos: 18
len: 6 | len: 10 | len: 2
row: 0 | row: 0 | row: 0
col: 0 | col: 7 | col: 18
lit: 'global' | lit: 'var_global' | lit: '10'
token: global | token: name | token: number_lit
} | } | }
4. 5. 6.
Token{ | Token{ | Token{
pos: 21 | pos: 26 | pos: 37
len: 4 | len: 10 | len: 5
row: 2 | row: 2 | row: 2
col: 0 | col: 5 | col: 16
lit: 'push' | lit: '"Hello!\n"' | lit: 'print'
token: push | token: string_lit | token: print
} | } | }
7. 8. 9.
Token{ | Token{ | Token{
pos: 43 | pos: 48 | pos: 59
len: 4 | len: 10 | len: 6
row: 4 | row: 4 | row: 4
col: 0 | col: 5 | col: 16
lit: 'push' | lit: 'var_global' | lit: 'uputln'
token: push | token: name | token: uputln
} | } | }
Numbers match numbers, text with quotes match strings, keywords match keywords and anything else that is valid text is considered a name.
It first tries to match keywords and names, then numbers. Finally it matches single line characters like quotation marks and comments using a big match statement.
Here is a very condensed version of the scanner, don’t worry if you don’t understand it in full!
fn is_valid_name(c u8) bool {
return (c >= `a` && c <= `z`) || (c >= `A` && c <= `Z`) || c == `_`
} // is this character valid?
fn (mut s Scanner) scan_token() ?Token {
if s.is_started { // increment cursor position
s.pos++
} else {
s.is_started = true
}
s.skip_whitespace() // skip whitespace
if s.pos >= s.cap { return none } // is end of file?
c := s.text[s.pos] // get current character
if is_valid_name(c) { // is the current character a valid
// keyword or name?
name := s.march_name()
kind := get_keyword_token(name)
if kind != -1 { // matched keyword! create token
return s.new_token(Tok(kind), name, name.len)
}
// create name token
return s.new_token(.name, name, name.len)
} else if c.is_digit() { // is the current character a valid number?
num := s.march_number()
return s.new_token(.number_lit, num, num.len)
// return number token
}
match c {
`"`, `'` { // is a string?
str := s.march_string()
return s.new_token(.string_lit, str, str.len)
}
`;` { // new comment, skip line
s.skip_line()
s.inc_line()
continue
}
// match more chars
// ...
else {}
}
return none
It is invoked like such, generating a entire list of tokens from the source file.
mut tokens := []Token{cap: 20}
for {
if i := scanner.scan_token() {
tokens << i
} else {
db.info("EOF hit, read $tokens.len tokens")
break
}
}
Just know, that a scanner performs “lexical analysis” on source code to generate a list of “tokens” that represent the source code along with other metadata like it’s kind and position in the source file.
It also handles errors like unterminated strings and unsuitable number literals:
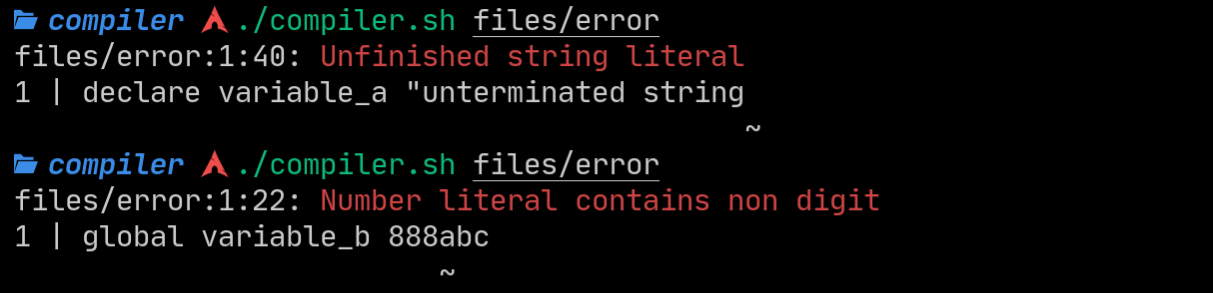
But that is at the token level, what about syntax errors? Like how variable specifiers must be followed with a name and then some data literal to be considered an actual declaration. Consider this:
global variable_c push
The scanner will parse this perfectly into the tokens:
[.global, .name, .push]
No errors on the scanners side, it’s not it’s job to uphold language conventions. However the next step, the Parser, is!
The Parser
A parser reads the output of the scanner in a stream of tokens. It verifies the syntax of the language (semantic analysis) and uses this information to generate data to be fed to the next step.
This “data” is usually in the form of an AST or abstract syntax tree. It defines branches, scopes and operations in a tree like format. Read more if you are interested because I absolutely do not do it this way. My language is quite linear, there is no need for an AST to be generated. This simplifies the compiler a lot.
The parser goes through the token stream one by one, using a big match statement to select tokens. Complex tokens like the push and pop operator or variable declarations require extensive checking.
Here is the match statement inside the parser:
match g.curr.token {
.declare, .global {
g.new_var()
continue
}
.push {
return g.new_push()
}
.print { return IR_PRINT{} }
.println { return IR_PRINTLN{} }
.uput { return IR_UPUT{} }
.uputln { return IR_UPUTLN{} }
.pop {
g.iter()
var := g.get_var(g.curr)
if var.spec == .declare {
g.s.error_tok("Declared variables are immutable",g.curr)
}
return IR_POP{
var: g.curr.lit
}
}
.add { return IR_ADD{} }
.sub { return IR_SUB{} }
.mul { return IR_MUL{} }
.div { return IR_DIV{} }
.mod { return IR_MOD{} }
.divmod { return IR_DIVMOD{} }
.drop { return IR_DROP{} }
.name, .number_lit, .string_lit {
g.s.error_tok("Unexpected name or literal",g.curr)
}
else {panic("Parser not exaustive!")}
}
For example the function new_var() would check for
- Incorrect literal data types
- Referencing other variables as value
- Assigning the string type to global variables
- Duplicate variables
Code that handles pop and push also checks if you use variables before they are declared. The pop operator also checks if the variable is a global, as globals are not constant.
String literals
String literals are treated like anonymous variables (think anonymous functions). They are placed inside the rodata sections in assembly and cannot be changed under any circumstance. The variable can be passed around, but never edited.
Inside the parser, pushing a string literal causes some extra code to be called.
push "String literal!\n"
fn (mut g Parser) new_push()IR_Statement{
g.iter()
if g.curr.token == .string_lit {
hash := unsafe { new_lit_hash() }
g.ctx.variables[hash] = Str_t {
name: hash
spec: .literal
tok: g.curr
}
return IR_PUSH_VAR {
var: hash
}
} // else if ...
}
The name of the “variable” is now governed by a hash function. A hash function transforms input into another, in a way that if the same input was put in the output would always be the same.
I use the unsafe decorator to allow my V function to keep a static variable that keeps its state over function calls. It starts at one and increments every time the function it called.
[unsafe]
fn new_lit_hash() string {
mut static index := 1
mut x := index
x = ((x >> 16) ^ x) * 0x45d9f3b
x = ((x >> 16) ^ x) * 0x45d9f3b
x = (x >> 16) ^ x
index++
return 'lit_'+x.str()
}
Calling the function 10 times always results in the same output.
"lit_824515495"
"lit_1722258072"
"lit_541708869"
"lit_850404657"
"lit_592649042"
"lit_1010202856"
"lit_148231923"
"lit_1700809315"
"lit_80224587"
"lit_1185298084"
Literal strings simply inherit this name and are passed onto the code generation section as variables!
Code Generation and Statements
Besides syntax checking, the parser coalesces one or more “tokens” into “statements”.
Source Tokens
push variable_a
push 1777
/=
Generated Statement
IR_PUSH_VAR{"variable_a"}
IR_PUSH_NUMBER{1777}
IR_DIV{}
The parser outputs these statements into the code generation step. These statements contain a dynamic code generation function that converts a statement into equvalent assembly instructions.
struct IR_ADD {}
fn (i IR_ADD) gen(gen &Gen) string {
return
' pop rdi
pop rsi
add rsi, rdi
push rsi'
}
struct IR_PUSH_NUMBER {data u64}
fn (i IR_PUSH_NUMBER) gen(gen &Gen) string {
return " push " + i.data.str()
}
/* To qualify as a statement, the struct must implement
a gen() function so it can be called by the codegen step. */
for s in g.statements {
g.file.writeln(s.gen(g))
}
The code generation step simply iterates over every statement, and writes its corresponding code into the assembly file. This allows for extremely dynamic code and keeps the compiler modular as statements at their lowest level are always the destination assembly.
Here is the code to generate the full assembly file. It first writes the assembly header, variables and builtin functions, then it generates dynamic code.
fn (mut g Gen) gen_all(){
g.file = strings.new_builder(250)
// -- HEADER --
g.file.writeln(header)
// -- VARIABLES --
mut s_data := strings.new_builder(40)
mut s_rodata := strings.new_builder(40)
s_data.writeln('section .data')
s_rodata.writeln('section .rodata\n\tbuiltin_nl: db 10')
for _, data in g.ctx.variables {
match data.spec {
.literal, .declare {
s_rodata.writeln('\t${data.gen(g)}')
}
.global {
s_data.writeln('\t${data.gen(g)}')
}
}
}
g.file.drain_builder(mut s_rodata, 40) // insert into file
g.file.drain_builder(mut s_data, 40) // insert into file
// -- BUILTIN FUNCTIONS --
g.file.writeln(builtin_assembly)
// -- START PROGRAM --
g.file.writeln(
' ; --- START ---
_start:'
)
// -- DYNAMIC CODEGEN --
for s in g.statements {
g.file.writeln(s.gen(g))
}
// -- EXIT PROGRAM --
g.file.writeln(
' ; --- END ---
exit:
mov rax, 60
mov rdi, 0
syscall'
)
}
The code varies on statement to statement, small calls to builtin functions don’t need much. When pushing and popping variables, types must be taken into account to generate correct code.
IR_PRINT{} // `print`
pop rbx
mov rdi, rbx
call builtin_strlen
mov rdi, rbx
mov rsi, rax
call builtin_write
IR_DIVMOD{} // `%%`
pop rdi
pop rax
xor rdx, rdx
div rdi
push rdx
push rax
IR_POP{"global_var"} // `pop global_var`
pop qword [global_global_var]
What is after code generation?
Here is a recap on the steps my compiler takes:
push "Hello!"
[Tok.push,Tok.string_lit]
IR_PUSH_VAR{"lit_824515495"}
push qword lit_824515495
But you ask, what comes after the assembly code is generated? Since this is NASM syntax, the NASM assembler must be called to finally generate the code.
First, a temporary filename is created to house the assembly and object files. This filename is created using another version of the hash function I use in the parser but with some changes.
file_write_tmp := os.join_path_single(os.temp_dir(),get_hash_str(filename))
This mix of functions joins the path of the temporary directory with a randomised but always same length string of lowercase letters. Examples and the exact hash function below:
"hello_world_file" = "/tmp/sudwexxd"
"output.asm" = "/tmp/slpdverm"
"compiler-test" = "/tmp/svjhokgd"
"rewrite_rust_in_V.stck" = "/tmp/pfawsadk"
fn get_hash_str(filepath string)string{
length := 8, seed := 0
mut x := hash.sum64_string(os.abs_path(filepath),seed)
mut s := strings.new_builder(length)
for _ in 0..length {
n := u8(x % 26 + 97)
x = ((x >> 16) ^ x) * 0x45d9f3b
x = ((x >> 16) ^ x) * 0x45d9f3b
x = (x >> 16) ^ x
s.write_u8(n)
}
return s.str()
}
After a filepath is generated, NASM and the linker are called to create the final executable:
file_write_tmp := os.join_path_single(os.temp_dir(),get_hash_str(filename))
os.write_file('${file_write_tmp}.asm',source)?
// write assembly file with a .asm extension
nasm_res := os.execute('nasm -felf64 -o ${file_write_tmp}.o ${file_write_tmp}.asm')
// create object file using NASM from the assembly
if nasm_res.exit_code != 0 {
eprintln(term.red("NASM error, this should never happen"))
eprintln(nasm_res.output)
exit(1)
}
os.execute_or_panic('ld ${file_write_tmp}.o -o $pref_out')
// execute `ld` and specify the output name
Closing notes
And thats it so far! The scanner, parser and code generation sections of the compiler.
My language right now is extremely limited, expect in the next post a lot more will be implemented. I’m looking to do a full redesign of a language and compiler, with functions and more datatypes.
Thanks for coming this far, see you in part three where I add a lot more features!