Creating A Compiler Part 3 - The `stas` programming language
It’s been a week, what’s changed?
Everything!
The first initial language was simply a demo, to learn the basics about code generation from top to bottom. This time, I did it for real. Here are some changes made between part 2 to now:
#include "std.stas"
main ! in do
"Hello World!" println
end
- Compiler and full language redesign
- Completely Turing complete with proper control flow
- if and while statements, recursive functions
- Standard library implementation in the language, no need for builtin assembly
- Support for stack variables and arrays
- Stack manipulation operators, arithmetic operators, comparison operators
- Working with pointers; dereferencing writing to memory locations
- C style code inclusions, better errors and proper calling conventions
- A new name and now public on Github!
I’ll go through the changes one by one, starting with…
Initial steps to language reform
The first thing in needed to be in order was some semblance of control flow. Conditionals and functions were needed.
Instead of evaluating top to bottom, the language and compiler now revolved around blocks of bodies containing further blocks of statements. Take a look at these new datatypes:
[heap] /* <- force allocation in heap memory */
struct Function {
mut:
name string // function name
args []string // names of function arguments
vari int = 1 // internal variable index
vars map[string]VarT // stack 64bit variables (pointers/u64)
bufs map[string]BufT // stack byte arrays
slit map[string]Token // string literals
body []IR_Statement // function body, stores all code statements
var_offset int // offset in the stack memory
buf_offset int // offset in the stack memory
is_stack_frame bool // does this call other functions?
no_return bool // does this return a value?
}
If you read the previous post, you know that all ‘statements’ can generate their own unique code. A list of statements make up a whole program. Works the same as before but with one difference, code now resides in functions. It all goes like this…
Statements can be as simple as a single instruction…
struct IR_DROP { }
fn (i IR_DROP) gen(mut ctx Function) string {
return '\tadd rsp, 8'
}
…or be arbitrarily complex, like this If statement:
struct IR_IF {
mut:
top []IR_Statement // conditional
body []IR_Statement // body
other []IR_Statement // else
}
fn (i IR_IF) gen(mut ctx Function) string
Keep in mind, for a ‘statement’ to be a ‘statement’, it must implement the gen() method. This is where the assembly is generated from. In the If statements case, calling the generate function kicks off the generation functions of all it’s inner statements. All joining together to create the final self contained code block. Moving on below:
#include "std.stas"
main ! in do
if 2 5 < do
"2 is less than 5!" println
end
end
./stas.sh files/main.stas -r
2 is less than 5!
This is a simple program that compares two numbers, it’s assembly is not too complicated. To make reading better, a new annotation is created when a new statement is parsed. As you can see, the less than conditional operator is the longest of them all.
I also added more annotations, this time manual, to denote the sections of this two part if statement. It makes no use of the third array, as this If statement does not contain an else block.
main:
push rbp ; Start If
mov rbp, rsp ;
main_if_xxxxx_begin: ; ?? IF - START ; ----+
push qword 2 ; <- LITERAL NUMBER ; |
push qword 5 ; <- LITERAL NUMBER ; |
pop rsi ; ~ CONDITIONAL - LESS THAN ; |
pop rdi ; |
xor rax, rax ; |
cmp rdi, rsi ; | top []
setb al ; |
push rax ; |
pop rax ; ?? IF - CHECK CONDITIONAL ; |
test al, al ; |
je main_if_xxxxx_end ; |
main_if_xxxxx_body: ; ?? IF - BODY ; ----+
push qword lit_xxxxx ; <- STRING VAR ; |
pop rdi ; + INIT FUNCTION ARGS ; | body []
call println ; + CALL FUNCTION ; |
main_if_xxxxx_end: ; ?? IF - END ; ----+
pop rbp
ret ; | RETURN TO CALLER
After this, I hope you can understand statments now. To recap, functions are at the highest level. They keep all their statements inside the function body. Statements can be arbitrarily complex, even containing other statements. Every statement evaluates to assembly code, no matter what. Statements containing other statements really opened up a way to create complex operations like while loops and if statements. On to the next section!
Recursive functions
To really open up more opportunities with the language, recursive functions really needed to be implemented. Luckily, I planned for this when I redesigned the language to eventually accommodate for functions.
One of my first programs using the new syntax was this recursive fibbonacci calculator, the original code was in C and it was pretty quick to port this over.
recurse_fibonacci in count do
if count 0 = do
0 return
else if count 1 = do
1 return
else
count 1 -= recurse_fibonacci
count 2 -= recurse_fibonacci
+= return
end end
end
int recurse_fibbonacci(int n) {
if (n == 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
return
recurse_fibbonacci(n - 1) +
recurse_fibbonacci(n - 2);
}
}
To allow recursive functions to work properly, there is a lot of setup that goes on behind the scenes. Managing variables, setting up stack frames and niche assembly instructions take up a portion of the startup and end code. Recursive functions utilise ‘stack unwinding’ to eventually return the value to it’s caller, I won’t talk about it because it’s above the scope of this post (go learn some C already!). Just know that function calling is a flawless, perfected process.
Pointers and stack manipulation
Take these two identical programs. Due to the nature of C style strings, you pass around pointers to the first element in a string and it’s length is determined by a 0 character at the end called the null terminator.
These two programs both dereference a memory address. In C, you use the star character. In my language it’s a litle different. Due to the absence of types, all stack values must have the same width (64 bits). You can still dereference a pointer with the star character, but it will default to a width of 64 bits. Essentially treating the memory location as an any bit sized number using the size specifier and either being 8, 16, 32 and 64 bits. The size of a ASCII/UTF-8 character is one byte, so I use 8 here.
#include "std.stas"
main in do
"Hello!" * :: 8
uputln
end
#include <stdio.h>
int main(){
char * hello_str = "Hello!";
printf("%d\n", *hello_str)
}
The star operator consumes a pointer from the stack, dereferences it, then puts the value on the stack to be consumed by other operators. Both of these functions will return 72, the character code for the capital letter H as it is the first character in the string.
To write to memory locations, I use the ampersand operator. It consumes two values from the stack. The memory location and the value to write. It also accepts a size specifier just like the star operator.
One more thing, the @ symbol means duplicate. Take the current value and push another onto the stack. It’s used in while loops to work on a duplicate value in the body before passing it back for the while loop to accept.
I’ll explain line 8
| |
- Start the stack with the pointer to the buffer (str_ptr)
- Duplicate this value
- Push the value 72 onto the stack
- Consume the duplicate and the value 72, write a byte to the duplicate pointer
- No more duplicate on the stack, increment the initial value
- Start over, take the duplicate of the previously incremented pointer
Running these steps over will completely fill up the 4 byte buffer. Check out its C equivalents below:
#include <stdio.h>
int main(){
char str_buf[4];
char *str_ptr = str_buf;
*str_ptr = 72; str_ptr++;
*str_ptr = 105; str_ptr++;
*str_ptr = 33; str_ptr++;
*str_ptr = 0;
printf("%s\n",str_buf);
}
#include <stdio.h>
int main(){
char str_buf[4];
str_buf[0] = 72;
str_buf[1] = 105;
str_buf[2] = 33;
str_buf[3] = 0;
printf("%s\n",str_buf);
}
The standard library
Before I implemented the new syntax, in part two, functions for printing strings and numbers were ‘built in’ to the language. Those functions were simply blocks of assembly copy pasted at the top of the file and called as necessary.
A goal of mine was to eventually rewrite them in my language. Here are the assembly builtin functions:
- println
- uput
- uputln
The ’ln’ versions of the function just append a newline after printing their respective types. I’ll talk about the ‘uput’ (unsigned number put) function as this was at a first glance, the hardest.
Converting a number to a string of characters is actually quite involved. You can’t just move a number right in, you need to extract each place value of the number, convert it to an ASCII character, and then place it in the string.
However, for unsigned numbers, this is quite easy.
1938
1938 % 10 = 8 -> 8, 1s place
1938 / 10 = 193
193 % 10 = 3 -> 3, 10s place
193 / 10 = 19
19 % 10 = 9 -> 9, 100s place
19 / 10 = 1
1 % 10 = 1 -> 1, 1000s place
1 / 10 = 0
- Start at your number
- Take remainder from dividing by 10, this is digit of the lowest place value
- Divide the starting number by 10
- Repeat with this number
The only thing you have to do now, is insert them into the string buffer backwards. Not too hard, wasn’t it?
To convert single digit numbers into single number characters, just add 48. 48 is the character code of 0 in ASCII and numbers 0-9 goes up to 57. Here is the unsigned put function in my language!
uput ! in num do
local buf [20] ; 18446744073709551615 <- largest unsigned 64 bit number
local pos 0
local len 0
if num 0 = do ; avoid division by 0
buf 48 & :: 8 ; '0'
buf 1 write
return ; early exit
end
buf 20 += pop pos ; move position pointer to end of buffer
; to insert in reverse
num
while @ 0 > do
pos -- pop pos ; decrement position
10 %% ; get remainder
48 += ; convert to ascii
pos ~ & :: 8 ; write char into buffer
len ++ pop len ; increment length
end
_
pos len write ; pass pointer and length to write function
end
Error handling and code inclusion
Want to use the standard library or any code snippet in your source file? Simple, just include it!
#include "std.stas"
Because I redesigned error handling and added file inclusions, figuring out what file the error came is needed. The compiler creates a scanner struct to scan a file, and all tokens generated from that scanner hold the file’s name that it was read from. If there is an error in the file you included, the compiler will let you know about it!
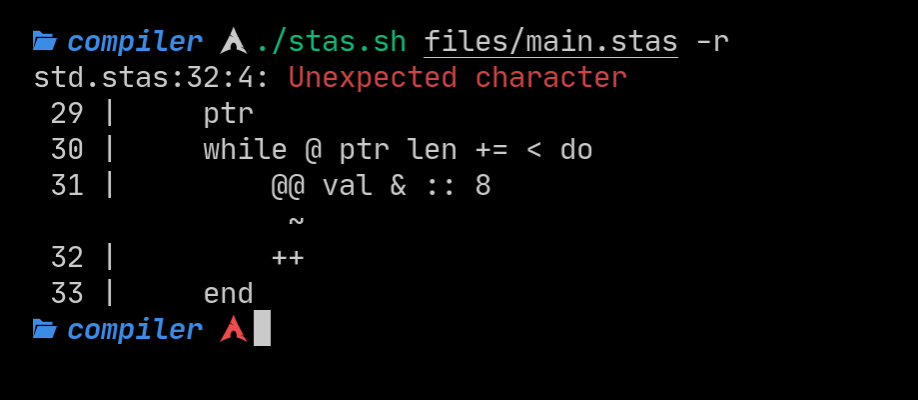
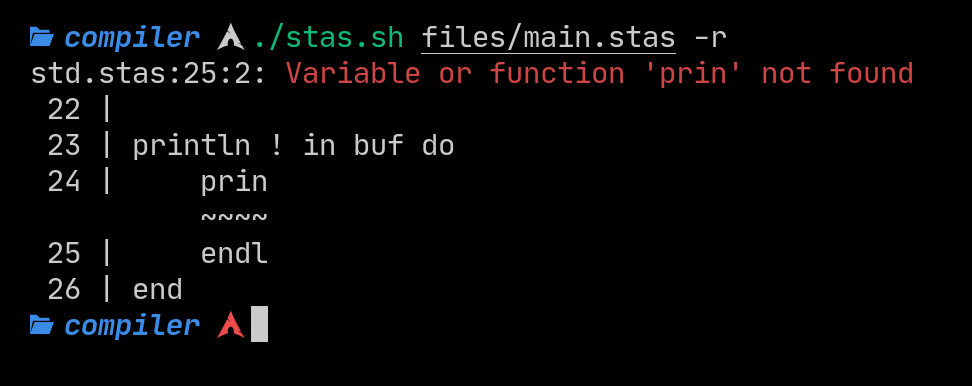
The compiler also warns you if you fail to provide a main function, as that is the entry point to the program.
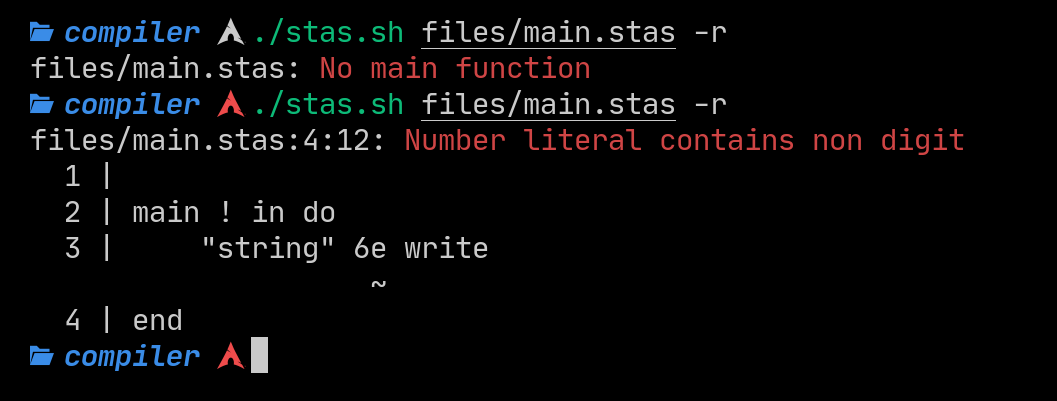
st(ack)as(sembly)
This is the stas programming language. A compiled, stack based, concatenative programming language. It’s also my first ever shot at something like this, I think I did a pretty good job at version 0.0.2.
You may still be very confused on the syntax of the language. I do not blame you, they don’t call it esoteric for no reason. This post was more like an update and information dump. In the next post I’ll really go into the details on how to develop in this language, because in the state it is right now, it is not user friendly at all.
I plan to implement some kind of static type system, verifiable at compile time. It will work by accepting statements and effectively soft simulate the program. This type checker pass is absolutely necessary for further development in the language as a small slip up can cause a segfault. It shouldn’t take too long to implement.
Once this type checker pass is implemented, I plan to add a ’tutor’ mode. It would effectivelly be a debugger showing the stack evolving with each function call and operation. It will not be an interpreter, it will simply show the flow of the program and types on the stack. I feel like this will really help people to understand the language a lot better.
Until then, I’m out!