Creating A Compiler Part 6 - Tiny Stas (A Complete Rewrite)
Intro
I want to write stas in itself.
This wasn’t a goal of mine in the initial compiler, back then I didn’t even know how to make one. I just worked with what I had, trying to create a programming language and compiler written in something existing, the V programming language.
My visons for a project often change, this is no exception. I wanted to write a compiler for my programming language, a very normal part of a compilers journey is to end up compiling itself.
Those are two programming languages that operate completely differently, number one being the absense of a stack based system in V. I was implementing stas in V a way that would be completely impossible to translate into stas later on. I was using a ton of abstracting features such as strings, dynamic arrays, an intermediary IR step (statements) and interfaces. V’s interfaces feature was how I implemented the code generation step and other parts of the stas compiler.
As you can tell, V is not stas.
The existing V codebase is extremely overengineered and relies heavily on V’s abstractions to function.
The only option that will actually get me to the goal of writing the stas compiler in stas would be to rewrite the existing one, to use pattens that would be easily reproducable in stas. So I did, I did do that.
All the new code is in a different branch called tiny-stas, waiting to be merged into the main branch.
Forgotten Code
I’ll gloss over what I implmenteted right after part 4, before the time I worked on the C projects.
C style variable refereces
#include "std.stas"
#use_dump
main ! in do
local int var 100
&var ; get the address of var
*64 ; dereference a 64 bit address
++ ; increment dereferenced value
&var ~ &64 ; place address of var and
; write to the 64 bit address
var uputln ; print the variable
end
Type checked pointers
#include "std.stas"
main ! in do
local int var 100
local *int ptr_to_var 0
&var pop ptr_to_var ; write the pointer to an integer var
ptr_to_var *64 uputln ; put ptr, deref, print
end
Replacing nasm code generation with fasm
format ELF64 executable
entry _start
segment readable writeable
lit_00001: db 'Hello world!', 10, 0
segment readable executable
main:
push rbp
mov rbp, rsp
sub rsp, 0
push qword lit_00001
pop rdi
call print
leave
ret
The linearity of stas
The old V implementation was not linear. It had statements containing arrays of statements. Having the compiler jump all over the place from different data to the next poses an issue, how would you allocate these arrays? There isn’t any dynamic memory allocation in stas.
stas is literally built as a linear language, why not build the compiler around that?
The new compiler works by working on one or more elements on a continuous array array and generating a new stream of data for each compiler pass. Transforming one set of data to another one after the other.
The new compiler pipeline is as follows.
(translate) (transform)
main.stas > | scanner | | preprocessor |
std.stas > > | scanner | > initial_tokens[] > | preprocessor | > tokens[]
io.stas > | scanner | | preprocessor |
(transform) (translate) (translate)
| parser | | codegen | | fasm |
tokens[] > | parser | > tokens[] > | codegen | > a.out.fasm > | fasm | > a.out
| parser | | codegen | | fasm |
Statements are redundant
Usually tokens in stas are a complete, single unit that contains no extra state or information. They boil down to one or more assembly instructions. Only with complex statements like if, while and functions are where more information needs to be encoded. Statements have been entriely replace with tokens.
The parser, like it’s name, parses the structure of the language.
So, if statements are gone how will while and if blocks work with no identifying information? Just tokens?
Tokens contain some state, they have one field of user data. This number is used for a wide array of things depending on the token type.
struct Token {
pos int
row int
col int
file_idx int
tok Tok
mut:
usr1 u64
}
Inside the parsing step, tokens that need to contain some state have their data filled in.
The ‘if’, ’else’, ’endif’, ‘while’, ‘do’ and ’endwhile’ blocks user data point to indicies in the token array. Those indicies are used link up their counterparts together to create their statement ‘bodies’. No complex statements needed.
.----+----------+---------+------+--------------+---------+-------+
+ 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|----+----------+---------+------+--------------+---------+-------+
- if | "hello!" | println | else | "hello two!" | println | endif |
`----+----------+---------+------+--------------+---------+-------+
| | | | |
+----------->>>-----------+ +-------------->>>------------+ +--> 0
.-------+--------+---------+----+---+----+-------+----------+
+ 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 |
|-------+--------+---------+----+---+----+-------+----------+
- while | double | deref64 | 10 | < | do | ptr++ | endwhile |
`-------+--------+---------+----+---+----+-------+----------+
| | | | |
+-------------->>>---------------+ +----->>>----+ +----------> 0
Tokens also do not contain a literal field, a string containing their literal representation in the source code. For most tokens this is not needed, but for variable names and string literals they are. These strings are stored in a seperate global array and their data field contains an index to these strings. When a string literal is converted into a token in the source scanning step, it’s inner data (the stuff between the quotes) is placed into the global string array. Numbers are also parsed right when they are turned into a token, having their value placed inside the data field too.
| |
Take this stas program. These are the new keywords that very directly express the end of a certain block (’endfn’ and ’endif’), they simplify parsing.
Here is it’s output in token form below.
After the scanning and preprocessing step.
tok line idx usr
func 0 0 0
name 0 1 0 ----\ 0: 'main'
do_block 0 2 0 | 1: 'greater than zero!'
number_lit 1 3 3232 | 2: 'println'
if_block 1 4 0 | 3: 'is zero!'
string_lit 2 5 1 ----| 4: 'println'
name 2 6 2 ----|
else_block 3 7 0 |----> name_strings[]
string_lit 4 8 3 ----|
name 4 9 4 ----/
endif_block 5 10 0
endfunc 6 11 0
After the parsing step. Functions are parsed here and it’s metadata is placed into another global array containing all the functions of the program.
Since the compiler is two passes, automatic function hoisting is easy. Functions can be used before they are declared, that is function hoisting. All functions are parsed then, inside the code generation step, checked if they exist before calling.
tok line idx usr
0: 'greater than zero!'
func 0 0 0 ---------> function_list[] 1: 'is zero!'
name 0 1 0 |
do_block 0 2 0 [0]-> Function { name_strings[]
number_lit 1 3 3232 <------\ name: main
if_block 1 4 7 --\ | argc: 0 ^
string_lit 2 5 1 | | retc: 0 |
name 2 6 2 | \---------- idx_start: 3 tokens[].usr1
else_block 3 7 10 <-+ /---------- idx_end: 11 |
string_lit 4 8 3 | | string_lits: [5, 8] --+
name 4 9 4 | | stackvars: []
endif_block 5 10 0 <-/ | stackframe: 0
endfunc 6 11 0 <------/ }
The preprocessor
Macros are extremely useful. They are used to make a sequence of tokens available to the programmer as a single macro token. Wherever the macro is placed, it’s body will be ‘copy pasted’ to where they are invoked.
Macros here are recursive too, that means macros expand and call more macros. The old implementation did not have them, an improvement was already made here!
define StackWord 8 enddef
define ptr++
double deref64 ++ write64
enddef
define ptr--
double deref64 -- write64
enddef
Functions and inline assembly
You see a ‘retc’ field next to the argument count field? That’s right, functions can return multiple values. Since they are still passed through registers to pass the stack frames boundary, there can be a limited amount of arguments and returns.
A short form of function declaration is allowed. Omitting the two argument and return values and just placing a do block right after means that the function will accept none and return none.
Here is the new function syntax to the right.
That last function, what does the ‘asm’ keyword do?
It allows you to write inline assembly inside stas. Similar to C inline assembly you can specify inputs and outputs, except these are passed through the stack.
Since the way stas is designed, each unit of assembly generated is it’s own self contained block of code interfacing with data through the stack. It doesn’t need to know the registers used in the instructions beforehand, just push and pop from the stack.
The input and output numbers are hints to the compiler that this block of assembly code will take two values from the stack and leave two variables when it ends.
fn voidfn do
10 drop
endfn
fn voidfn_explicit 0 0 do
10 drop
endfn
fn taketwo 2 1 do
drop drop
10
endfn
fn swap 2 2 do
asm 2 2
" pop rdi
pop rsi
push rdi
push rsi"
endfn
Inline assembly means that the compiler can have a limited amount of reserved intrinsics with the rest being implemented in inline assembly right inside the source code. Math operations are usually compiler instinsics while stack manipulation functions are implemented with inline assembly. It doesn’t have to keep track of a thousand different intrinsics anymore.
Less work for the compiler, the better.
Macro’s are essentially copy pasted into where it is invoked during preprocess step. Since there is no optimiser yet, using a macro reduces instruction overhead due to omitting the call entirely.
The swap and dup (duplicate) stack manipulation functions are implemented with a macro.
define dup
asm 1 0
" add rsp, 8"
enddef
define double
asm 1 2
" mov rdi, [rsp]
push rdi"
enddef
fn main do
10 11 swap
drop
drop
endfn
Lack of type checking
Honestly, strict type checking felt like more of a hinderance than help. There isn’s much need for type checking when all variables and values are the same size anyway, 64 bits.
The only thing a stas compiler would be required to implement is checking for unhandled stack values on a function return and balancing the stack on each branch of an if statement.
Type checking added so much to the codebase (500 lines) with a quite minor payoff. Why call a completely seperate compiler pass to deal with this anyway??
If you are just managing a simple variable that you increment and decrement to keep track of the stack, why not merge it with codegen?
fn genone(_stackdepth int, _ipos u64, f Function) (int, u64) {
mut stackdepth := _stackdepth
mut ipos := _ipos
match tokens[ipos].tok {
.inc {
if stackdepth < 1 {
compile_error_t("not enough values on the stack to consume", ipos)
}
writeln('pop rdi')
writeln('inc rdi')
writeln('push rdi')
}
.shl {
if stackdepth < 2 {
compile_error_t("not enough values on the stack to consume", ipos)
}
writeln('pop rcx')
writeln('pop rdi')
writeln('shl rdi, cl')
writeln('push rdi')
stackdepth--
}
// ...
// ...
// ...
}
return stackdepth, ipos
}
| |
It’s very important to balance the stack on both if and else branches. You could end up with dangling values on a functions return or weird behavior after a string of function calls.
This is kept track inside the code generation section too.

Error handling isn’t as expressive anymore. It isn’t top priority right now, baby steps. However, there is enough data provided when an error does occur to allow a full visual later on.
Reserving stack memory
You can reserve bytes on the stack like this.
reserve 21 buf1 ; new syntax
reserve 31 buf2 ; new syntax
local * buf1 [21] ; old syntax
local * buf2 [31] ; old syntax
There is no notion of variabies, yet. Just 8 byte sections of stack memory used to store values.
The deref and write keywords can be used to read and write from pointers. The bit length appended after can be used to specify what size the data that pointer points to is.
define StackWord 8 enddef
fn main do
reserve 20 buf
reserve StackWord pos
reserve StackWord len
pos 16 write64 ; write 16
pos deref64 ; deref memory
endfn
The language right now does not have structs built in to the compiler, but they can be emulated using macros. This is exactly how NASM implmentents structs, with each field being a macro expanding to an offset.
include "lib/std.stas"
define sizeof(mystruct) 12 enddef
define mystruct.a 0 enddef
define mystruct.b 4 enddef
define mystruct.c 8 enddef
; 1: offset, 2: idx
define read_at_idx
sizeof(mystruct) * +
mystruct[10] +
deref32
enddef
; 1: offset, 2: idx, 3: data
define write_at_idx
rot
sizeof(mystruct) * +
mystruct[10] +
swap write32
enddef
fn main do
reserve 120 mystruct[10]
mystruct.a 1 888 write_at_idx
mystruct.b 3 777 write_at_idx
mystruct.a 1 read_at_idx uputln
mystruct.b 3 read_at_idx uputln
endfn
define sizeof(mystruct) 12 enddef
define mystruct.a 0 enddef
define mystruct.b 4 enddef
define mystruct.c 8 enddef
fn main do
reserve mystruct sizeof(mystruct)
mystruct mystruct.b + 888 write32
mystruct mystruct.b + deref32
uputln
endfn
Arrays of structures in stas will be quite easy to pack and get memory offsets from. Since writing to or reading from can be used with a memory location, just getting a pointer in an array of that struct would be quite easy.
Support for global memory is not supported yet but I’ll probably get to work doing it as soon as this post goes out.
The end for now
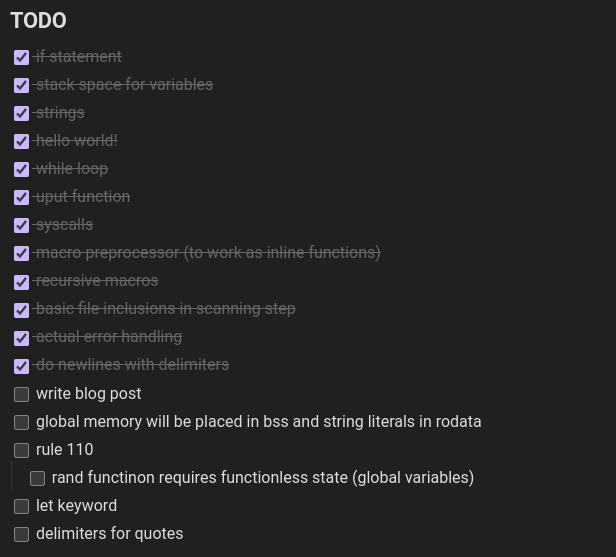
It only took four days of on and off writing to complete a basic stas compiler and all of the above.
It’s an understatement to say that the codebase is so much easier to work with.
I’d say that’s pretty good! I am not giving up on this thing anytime soon, not until the compiler can compile itself and generate optimised code. Until then, I will not stop till this language is decent.
The stas programming language and it’s compiler is constantly evolving. I mean, the syntax get’s an overhaul every second commit. Give it a couple weeks, since it’s the school holidays I have an unlimited amount of time to work on it.
Goodbye for now!