Creating A Compiler Finale - stas 0.1.0
I’m going to be real with you. I did pull a time jump.
The language and compiler is finally static, and the compiler is selfhosted.
Hold on, I’ll give you some context.
Part 6 Kind Of Sucked.
If you haven’t read it, I’ll tell you what went down. Essentially I rewrote the compiler, removing the high level abstractions and bloat, embracing a linear design with a new syntax absent of type checking. Those parts, good!
Now the bad parts. Moving intrinsics out of the compilers eye to macros with inline assembly was a bad one, especially since that the current compiler does optimisation. Another bad thing was the removal of intermediate representation, just going off of tokens to generate code. An intermediate representation is very important in a compiler. Bare machine instructions can’t be poked and prodded, It’s useless once that text is generated.
Adding in macros and removing the IR was the worst ideas I have ever had. I thought I was removing complexity, instead I was adding more in.
All About The Balance.
Don’t make a language with very simplistic features or it will be pain to selfhost. This was the fault of the new compiler in part 6.
To add those features to the bootstrap compiler don’t use too many abstractions otherwise it will also be impossible to selfhost. This was the fault of the original compiler.
I wanted to implement stas in a way that makes the compiler powerful.
Once I wrote compiler part 6, I took some time off to do some research and look for alternatives. The real reason why I stopped working on the new compiler I described in part 6 is because it got out of hand, exactly like the original one.
I came back with a fresh mind and rewrote the compiler for a third time.
I am really proud of It’s current state. Absent of unneeded recursion, the compiler’s design is simple and straightforward. The generated code is also decently optimised. Now working register to register, abstracting away the pushing and popping from the view of the programmer.
Branches are now relative and an instruction in the compilers IR, this allows for function inlining to be as simple as a straight copy paste of the function body to the calling location. Ironically, adding the IR back as a part of the compiler made it more linear.
A Recursive Parser.
Before I show you the new syntax, take a look at this code from the old syntax.
0 if
1 if
; branch if
else
; branch else
endif
else
; branch else
endif
How would you think this code would be parsed?
Lets say you are in the middle of parsing an if statement and you encounter another one, a nested if statement. What do you do?
In this case, recursion is useful here. Peek at the python pseudocode on the left.
def parse_one():
pass
def parse_if():
if_branch = curr_tok_pos
else_branch = 0
for a in all_tokens:
if a == if_token:
parse_if() # recurse!
elif a == else_token:
else_branch = curr_tok_pos
elif a == endif_token:
break
else:
parse_one()
def parse_all():
for a in all_tokens:
if a == if_token:
parse_if()
else:
parse_one()
Each complex block, which is anything that requires some context such as references to other tokens, has a function for handling it.
In the parsing loop, where each token is iterated over, the if token is checked for. If it finds one, it calls the corresponding function. Inside the if parsers loop the if token is also checked for, which then does a recursive call.
Recursive functions are great because each instance of a function keeps their own local variables and state, working on a problem in a form of ‘divide and conquer’ method. It’s all self contained. Recursion is very useful in compilers and in general. The same function going along and parsing the if case can just call itself if it comes across another one.
Sounds easy on paper? It’s an edge case nightmare.
Recursion was the one thing that made it impossible to synchronise everything, it was also made worse with no intermediate representation. That forced other stages to go through the exact same recursion pattern to extract any kind of data. In short, it made everything incredibly painful.
Forget It, I Have Something Better.
This is the scope stack. This is how complex keywords and scopes are implemented.
If an case was just reached, push an if scope onto the scope stack.
0 if <---- token_stream[pos]
1 if |
; branch if |
else |
; branch else |
endif |
else | /-----------\ <----- scope_stack.len
; branch else | | if_case |
endif \-> \-----------/
Another if case? Exactly the same as before, push one more.
0 if
1 if <---- token_stream[pos]
; branch if |
else | /-----------\ <----- scope_stack.len
; branch else | | if_case |
endif \-> \-----------/
else /-----------\
; branch else | if_case |
endif \-----------/
Each complex block manipulates the stack in It’s own way. If you reach an else keyword, make sure that an if scope is on the stack, and pop it off. Then, push an else case to be handled down the line.
0 if
1 if
; branch if
else <---- token_stream[pos] /-----------\ <----- scope_stack.len
; branch else | | else_case |
endif \-> \-----------/
else /-----------\
; branch else | if_case |
endif \-----------/
The end if keyword would have multiple uses. If an if case was on the top of the stack, the parser would know that an else branch would not exist, and vice versa. Anyway, the second if statement is complete and handled by the parser in It’s entirety.
0 if
1 if
; branch if
else
; branch else
endif <---- token_stream[pos]
else /-----------\ <----- scope_stack.len
; branch else | if_case |
endif \-----------/
Moving on, the first if case can finally be handled.
0 if
1 if
; branch if
else
; branch else
endif
else <---- token_stream[pos] /-----------\ <----- scope_stack.len
; branch else | | else_case |
endif \-> \-----------/
0 if
1 if
; branch if
else
; branch else
endif
else
; branch else
endif <---- token_stream[pos] ............. <----- scope_stack.len
With this method you don’t need recursion at all. The current parser is just a straight loop going over each token one by one. Infinitely better. You can create and nest as many scopes and statements as you want and they will all be handled perfectly. Last scope in, first scope out. Fitting for a stack based language.
With this stack based scoping, you get a ton of things for free.
fn main 0 0 {
reserve variable_name 2
1 if {
reserve variable_name 8
}
{
reserve same_name 4
while 1 {
reserve same_name 1024
}
}
}
One of these advantages is easy variable scoping. Check out the new syntax on the left.
A good thing about some programming languages is you cannot reference variables outside of their current scope. Variables can also have the same names has others in lower or higher scopes.
Function local variables are also stored as a stack. When a new scope is pushed onto the stack, the position of the highest element in the variable stack is stored. Inside this scope, new variables can be added and name collisions are checked inside this scopes ‘frame’. When a scope gets popped off, variable stack is rolled back to It’s previous position, releasing all of the old variables.
Besides basic scopes that do nothing other than variable shadowing, more complex ones like if and while scope contain more data. The current simulated stack pointer and a label can be stored in there if it needs one.
The entire parser has been replaced with a stack based implementation, not a recursive one. That has made all of the difference.
Code Generation And IR
What does the parser actually generate? Intermediate representation.
Like I said before intermediate representation is incredibly nice to have. In stas, It’s a sort of lower level middle ground between tokens and bare assembly instructions in text form. One stores unnecessary information, and another is absolutely useless once generated.
The intermediate representation is a form that can be easily manipulated, optimised and have code generated from it. Some examples? Look below.
Data
Inst.push_str
Inst.push_num
Inst.push_argc
Inst.push_argv
Control Flow
Inst.do_cond_jmp
Inst.do_jmp
Inst.label
Inst.fn_prelude
Inst.fn_leave
Inst.fn_call
Stack Ops
Inst.swap
Inst.dup
Inst.over
Inst.over2
Inst.drop
Arithmetic
Inst.plus
Inst.sub
Inst.mul
Inst.div
Inst.mod
Inst.inc
Inst.dec
This stas code will be scanned into a token representation, parsed into IR and converted into x86-64 assembly code.
fn main 0 0 {
52 11 + 99 - drop
}
Inst.fn_prelude -> main
Inst.push_num -> 52
Inst.push_num -> 11
Inst.plus
Inst.push_num -> 99
Inst.sub
Inst.drop
Inst.fn_leave -> main
main:
mov [_rs_p], rsp
mov rsp, rbp
mov rbx, 52
mov rsi, 11
add rbx, rsi
mov rsi, 99
sub rbx, rsi
mov rbp, rsp
mov rsp, [_rs_p]
ret
How does this work with the most basic form of control flow statement, the if case?
All an if statement is at the low level is a conditional jump over the code inside it. False? Jump over. True? Do not jump and allow the body to be executed. Scopes are perfect for this, generating instructions at the start and keeping state for when the if scope is closed.
cmp rax, 0 ; compare to zero
jz end_if ; jump if zero --\
; |
mov rsi, 10 ; do if true |
; |
end_if: ; -<<<<----------/
ret
void function(bool value) {
if (value) goto end_if;
printf("ironic, "
"but you get the point.\n");
end_if:
}
You can see why a field dedicated to a label inside a scope in the stack is so useful. When encountering an if token, get a new label and pass it to the scope to be pushed onto the scope stack. Before exiting, put an IR instruction for a conditional jump referencing the label.
Let the parser chug along, generating the IR for rest of the tokens in the if’s body. But when it hits a closing curly bracket and the scope on the top of the stack is an if case, all it has to do is to put that label there!
See the IR generated for this function and It’s assembly output below.
fn main 0 0 {
1 if {
; true
}
}
Inst.fn_prelude -> main
Inst.push_num -> 1
Inst.do_cond_jmp -> 0 \
Inst.label -> 0 /
Inst.fn_leave -> main
main:
mov [_rs_p], rsp
mov rsp, rbp
mov rbx, 1
test rbx, rbx
jz .0
; true
.0:
mov rbp, rsp
mov rsp, [_rs_p]
ret
Writing stas In stas.
I wasn’t just doing nothing during the time jump. I wrote the entire compiler in itself and deprecated the V compiler.
A big reason why it was quite simple to implement the compiler is stas was because the V code was extremely low level. Unsafe keywords, global variables, pointer arithmetic, memcpys, nul terminators everywhere.
__global string_buffer = [65536]u8{}
__global string_buffer_len = u32(0)
type StringPointer = &u8
[unsafe]
fn push_string_view(ptr StringPointer, str &u8, len int) {
assert *(&u64(ptr)) != 0
assert len > 0
if string_buffer_len + u32(len) >= 65536 {
panic('used up all memory')
}
unsafe {
ptr_pl := &u8(ptr) + sizeof(u64) + (*&u64(ptr))
vmemcpy(ptr_pl, str, len)
*(&u8(ptr_pl + len)) = 0
*(&u64(ptr)) += u64(len)
string_buffer_len += u32(len)
}
}
The current V compiler is stashed away in a seperate branch. The V compiler’s code supports all code written before version 0.1.0. The stas compiler however, is not static, It’s constantly being iterated on.
Here is the git commit messages from when the stas compiler was started to when both compilers where equivalent.
-* 27cce4e (tag: 0.1.0) stasc: now builds in 20 ms!
-* 34f40b9 stasc: V has been exiled
* d899ac6 stasc: V compiler and stas is equivalent
* bf4f0cd (origin/0.1.0-v-compiler, 0.1.0-v-compiler) stasc: the stas compiler.
-* c87f36f stasc: STAS CAN FUCKING COMPILE ITSELF
+* 8b043a3 stasc: parser is equivalent
* 8cc70bc compare add.stas with v and stasc
* b4d9400 stasc: leaving for now, get to root cause later
* c082b03 stasc: so close, r_drop segfaults
+* 1a7c987 stasc: buffered io
+* 1aff903 stasc: dce and boolean not operator (long enough)
* 9bace0f stasc: testing out name mangling
+* f1238cb stasc: x86 reg
* 9caa279 initial x86 reg allocator
+* b4211b5 stasc: can now parse the entirety of stas.stas!
+* e9fafb4 stasc: constants, entire parser.stas done!
* dfb0128 stasc: parsing constants, need to create evaluator
* 3640bc5 stasc: all variables, constants to go
+* 500d679 stasc: calling functions
* 47dfcd3 stasc: parser needs to resolve names
* 62cfbb4 stasc: parser basic while impl
* 06eb36a stasc: parser basic scoping done!
* c79643e stasc: parser half scopes
* 85ac3ed stasc: parser short leg done
+* 97d6ca5 stasc: init parser defs
* 2c91f96 stasc: errors
* 8a5fdaa Merge branch 'master' of https://github.com/l1mey112/compiler
|\
+* | 9fde84f full scanner implementation in stas
| * 2a3ca68 Update README.md
|/
* f06bc1c scanner scanning individual tokens
* bb63cbe scanner almost done not working though
+* 6ab908e starting stas scanner
This was the screenshot I took right after stas was able to compile itself. I proved It’s self hosting ability by creating a stas compiler with the V compiler, then using that compiler to compile another stas compiler.
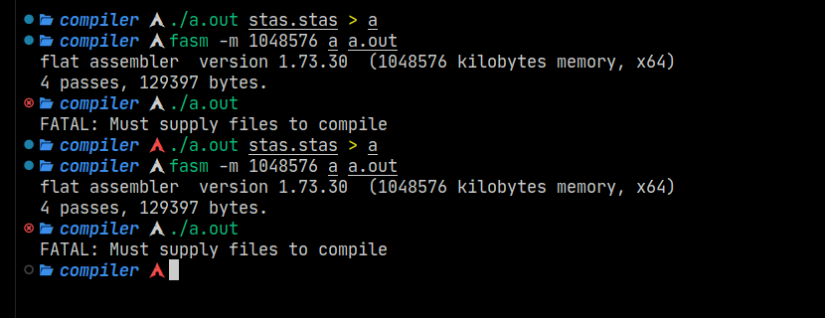
The part that took the longest? The parser. It has a large amount of data structures that all need to be handled individually, generating the IR, parsing function calls, global and local variables and scoping all needed to be implemented.
The end.
The name of the series is called ‘Creating A Compiler’ - It’s safe to say the project has grown into something more. It’s not about creating a compiler, It’s about creating stas. A stack based programming language. It’s not some toy language anymore.
The reason why I refuse to show much syntax of stas is because I am saving it for a future article, sometime soon.
I want to write a few more posts about compiler theory and how stas works under the hood. I want to talk about the types of optimisations I use, compile time evaluation, the intermediate representation and code generation. All of that good stuff.
Guides on how to program in stas is also something I want to do soon, since there isn’t much documentation.
I finished what I came for anyway, I have a working programming language and self hosted compiler and can now work on the language directly. Expect updates and version bumps in a decently consistent timeframe.
I am happy to say goodbye to you all.