Convincing corrupted file generation
Intro
Before I switched to linux, I used a windows program for generating files with garbage data to pass them off as corrupted files. after learning V, I wanted to take it a step further and inject magic signatures into the file for it to be recognized by software, increasing it’s legitimacy.
me - V discord
Magic numbers / file signatures
How do programs tell the difference between text files and PDFs? PNGs and JPEGs? You would probably say the file extension, but it’s usually never enough.
Sure, inside windows the file extension gives hints to the operating system on what software to hand the data off to. But what if the the file got renamed? What about the multiple types of executable files? How would you tell the difference between those?
Forget file extensions, how do programs actually know what file format they are dealing with?
File formats usually use file signatures that prove to software that they are what they say they are. A string of unique data or “magic numbers” outlined in the format’s specification is enough. This data is usually put at the start of the file and is usually called a “header”. Most of the time they are something simple like a couple bytes but some encode other arbitrary information.
Most software interfacing with files check for file signatures as a quick sanity check, no one wants to interpret the file in it’s whole. How do you fake them? It’s dead simple.
Windows EXE files encode the hex data 4D5A translating to the the (magic) numbers 77 and 90 at the exact start of the file. To fake them, just open up your favorite hex editor, and put them in! (with at least some padding)
But that’s tedious and annoying. The last thing programmers ever want to do is anything by hand, you have to automate everything!
There are datasets containing the file signatures of a lot of formats, I took a JSON one from a gist.
Interpreting the data is easy. The string on the left side of the comma should be read as the data offset, while the actual hexadecimal data is on the right.
"m4a": {
"signs": [
"0,00000020667479704D344120",
"4,667479704D344120"
],
"mime": "audio/mp4"
},
Here is some quick and dirty code that does its job pretty well. Just pipe the output to a file and you’re done!
import encoding.hex
const signs = [
"0,00000020667479704D344120"
"4,667479704D344120"
] // apple m4a file
fn main(){
mut file := []u8{}
for sign in signs {
tmp := sign.split(",") // split string in two
offset := tmp[0].int()
data := hex.decode(tmp[1])? // decode the hex values
for _ in 0 .. offset { file << 0 }
// pad the file with zeros for an offset
file << data
// append byte data to the array
}
print(file.bytestr())
// print to stdout with the direct binary data
}
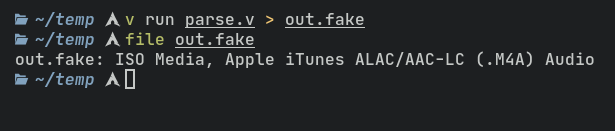
The final program
It compiles to a self contained executable that does exactly what you think it does. It uses a CLI to specify the extension, size in MBs and output filename. You can also list all formats and their “mimetypes”.
Have fun checking it out!