The C REPL
The shortcomings of igcc
IGCC is a real-eval-print loop (REPL) simulator for C/C++ programmers. It allows you to type C++ commands which are immediately compiled and executed. Underneath it uses the normal GCC exe for compiling.
I’ve been using igcc to just play around with C here and there. For small programs it works pretty fine but still leaves a lot to be desired. Multiline input wasn’t properly supported, even defining functions weren’t possible.
So I thought, how hard could it be?™
Welcome to crepl!
I started writing crepl the week I had australian highschool ‘work experience’, so I had to work around it. It took 3 days to complete the first version and I’m pretty happy with it!
crepl adds these new features:
- Multiline input
- Functions, typedef and struct declarations
- Pure C compiler
- Near instant compilation
- Proper indent formatting
- Simple syntax highlighting
When I started this project, I knew I was going to be dealing with a lot of strings. Mallocating every time I wanted to input text to the compiler would add up in a lot of slowdown. Speed, as always, was one of my main goals.
I Realised early on that string concatenations were where most of the heap allocations where going to be taking place. V allocates a new string for every concat, where instead I allocate one big buffer to encompass all concatenations.
I also take advantage of ‘buckets’. Take a look at this igcc output:
$ igcc
igcc 0.1
Released under GNU GPL version 2 or later, with NO WARRANTY.
Type ".h" for help.
....
....
g++> .L
#include <cstdio>
#include <iostream>
#include <string>
using namespace std;
int main()
{
void this_fn() {
printf("Hello!\n");
}
struct Hello {
int a;
};
return 0;
g++>Forgetting about the obvious lack of formatting, you can see that functions and structs are being dumped inside the main function. This obviously cannot do. To fix this issue, I use 5 source code ‘buckets’ that serve the purpose of holding position dependent code, those 5 are for:
- #includes
- Structs and typedefs
- Hoisted function declarations (todo)
- Function bodies
- Main Function
When a line is input into crepl, it uses a collection of rules to determine what bucket it should go into. On multiline inputs the first line is only parsed. Take this block of code from crepl:
const c_types = [
'void'
'int'
'double'
'float'
// ...
// ...
]
// assume line is already stripped of whitespace from start to end
fn (mut r CREPL) parse_inital_line(s string) int {
if s.contains("=") {
return 4
} // apparently?
if s.starts_with('#') {
return 0
} else if
s.starts_with('struct') ||
s.starts_with('typedef')
{
return 1
}
// function 'parsing'
for ct in c_types {
if s.starts_with(ct) {
if !s.contains("(") {
break
}
return 3
}
} // use binary search (highlight.v)
return 4 // main()
}It relies on some very simple facts about the C
lanuage. Struct, function and typedefs never use the
equals sign so we can weed that out pretty quick. The
hash symbol always means an include and if a line
contains a type and a bracket somewhere it is always a
function declaration. If it does not match any of those
conditions, for example an int a; , it
just simply returns the main bucket.
When joining all the source code buckets together I
simply get the lengths of all, then use the shift left
operator to concatenate them. The array concatenate
operator is just a simple memcpy under the hood, barely
a performance hit there. Finally I call the
str() method on the string builder that
returns all the built up data as a string.
struct SourceBucket {
mut:
source strings.Builder
}
const source_bucket_count = 5mut len := 0
for b in source_buckets {
len += b.source.len
}
mut a := strings.new_builder(len)
for idx, b in source_buckets {
a << b.source
}
return a.str()unsafe {} !
My approach to an undo and redo history system is quite unorthodox.
struct HistoryRecord {
history_idx int
source_bucket int = -1
}return CREPL {
// ...
history: []HistoryRecord{cap: 20}
}I preallocate a buffer of 20 history records. My history records contain two things, a number from 0-4 determining what source code bucket it came from and the index in the string buffer at that point in time.
Want to push a history record? Simple:
fn (mut crepl CREPL) push_history(b int) {
crepl.history << HistoryRecord {
history_idx: crepl.source_buckets[b].source.len
source_bucket: b
}
// ...
}Want to undo? Just decrement the current history index, read the history record at that location and forcibly overwrite the bucket’s array length with the history record index.
crepl.current_idx-- // decrement internal index
rec := crepl.history[r.current_idx]
unsafe {
crepl.source_buckets[rec.source_bucket].source.len = rec.history_idx
}The undo and redo operations change an internal index by incrementing or decrementing it.
Like most repls, you can only add and overwrite code. It’s all perfectly linear. That means you can get away with cheap but fast hacks like this one.
- Push the current state to the history
- Make your changes
- Undo? Step back to the old buffer length
All the history system is, is a collection of array lengths being used to overwrite sections of the dynamic array…
// write 'int a;'
[`i`,`n`,`t`,` `,`a`,`;`,`\n`]
// ^
// len
// mark history
// write 'int b;'
[`i`,`n`,`t`,` `,`a`,`;`,`\n`,`i`,`n`,`t`,` `,`b`,`;`,`\n`]
// ^ ^
// history 1 len
/* int a;
int b; */
// undo to history 1
[`i`,`n`,`t`,` `,`a`,`;`,`\n`,`i`,`n`,`t`,` `,`b`,`;`,`\n`]
// ^
// len
// write 'a = 10;'
[`i`,`n`,`t`,` `,`a`,`;`,`\n`,`a`,` `,`=`,` `,`1`,`0`,`;`,`\n`]
// ^
// len
/* int a;
a = 10; */Changing the length of an array may be considered ‘unsafe’ because it may be greater than the actual allocated memory, leading to memory accesses greater than the bounds of the array. Since I only make the length smaller, it seems fine.
How many braces?
Proper formatting and multiline input, unlike a history system, was a new feature. Once I implemented multiline input, formatting came very easily. Take a look at this input:
cc $ struct A {} # all braces resolved, do not enter multiline
cc $ struct B { # 1 brace left, enter multiline
.... int a;
.... int b;
.... };
cc $ The repl keeps an internal counter that keeps count of the unresolved braces still left.
r.count_braces('struct A {}') // r.brace_level = 0
r.count_braces('struct B {') // r.brace_level = 1
r.count_braces('}') // r.brace_level = 0When figuring out what to do with a line it counts all the braces, if there are some braces still left unresolved it changes the prompt to an indent and writes to the multiline source buffer.
if r.brace_level != 0 {
r.prompt = prompt_indent
r.multiline_source.write_string('\t'.repeat(r.brace_level))
r.multiline_source.writeln(line)
continue
}What about line 3? Remember how I said implementing one led the way to implementing the other? Writing a new tab character for every brace works perfectly for formatting nested scopes.
Syntax highlighting
I’ve already written a tokenizer for stas, why not repurpose it for syntax highlighting?
I’m pretty proud of this one, it’s as optimised as I think it can get.
[direct_array_access]
fn format_c(s string) string {
mut b := strings.new_builder(s.len+60)
mut f := token.new_keywords_matcher_trie<Sc>(c_keywords)
// does binary search on keywords
mut pos := -1 // current position in source
mut clean_pos := 0 // earliest position that has not been matched
for {
pos++
pos = skip_whitespace(pos, s)
if pos >= s.len { break }
c := s[pos]
if is_valid_name(c) {
mut name := ''
oldp := pos
name, pos = march(pos, s)
kind := f.find(name)
if kind != -1 {
b.write_string(s[clean_pos..oldp]) // flush
b.write_string(c_keywords[name](name)) // write coloured
clean_pos = pos + 1
}
}
// match single characters
// #, {}, (), ;, ', "
}
b.write_string(s[clean_pos..pos]) // flush the rest
return b.str()
}It uses a position variable to march throughout the source code, then when it finds a match it flushes from the clean position to the current position. It then colourises this match, writes it out and sets the clean position to ‘step over’ the coloured keyword.
This way is much better than concatenating every single character. For code with lets say, 8 keywords, it would only do 17 writes regardless of how huge the initial source code string is.
I also use a builtin function V uses inside it’s compiler to match tokens. It uses a binary search to automatically match keywords.
Why I use TCC
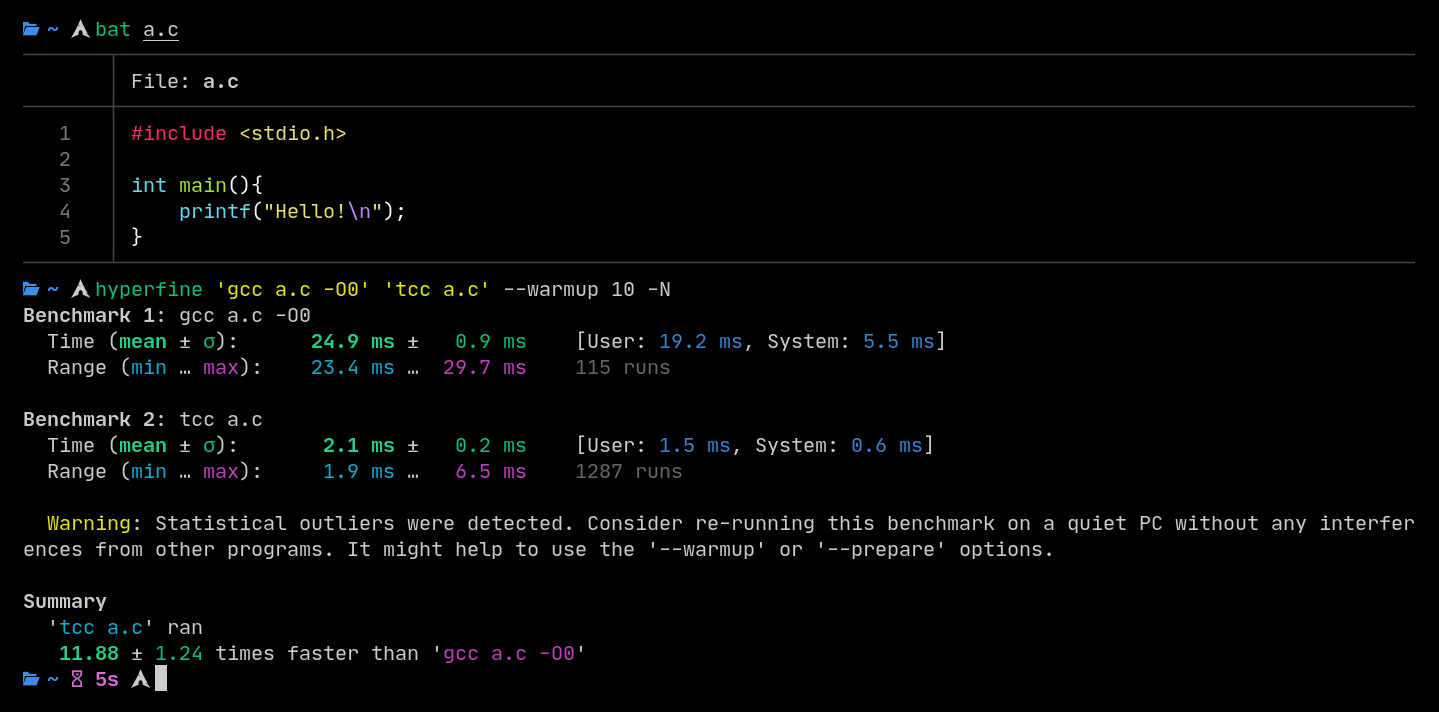
In a situation where spitting out a binary in the fastest time is critical, TCC is the obvious choice. It’s also used for fast compilation in the V langage and it’s what I use in crepl.
I’ve seen 10 to 20 times speedups putting GCC against TCC. Clang even longer still, where I’ve seen a 30 times speedup. Both are optimising compilers and even turning them off doesn’t save them.
Using the --cc flag when starting up
crepl allows you to force a compiler to be chosen.
Closing up
I chose to tackle the task of a C repl because I wanted an enviroment where I can quickly prototype a C program without opening up an IDE or vim.
I hope a lot of people find this useful, because I sure did!