Intro To The stas Programming Language - Variables And Memory
- As of writing, stas is in version 0.1.3.
The Importance Of Variables.
Not every algorithm, program or programmer can stay in the stack forever. Variables have their place in programming languages, and stas is no different.
There are three types of variables in stas, and they all serve their own purpose.
A variable is a name given to a piece of memory our programs can manipulate. Either stored in the stack local to a function, or globally, not contained inside any functions.
The name of a variable in stas, just like functions, can be absolutely anything. Not restricted to just letters, digits or underscores, stas indentifiers can be any Unicode character except whitespaces.
Buffers Of Bytes.
In stas, you have the option to reserve bytes of memory with the reserve keyword. Start with the reserve keyword, then a name, then finally the size in bytes.
reserve <variable_name> <count>
char *variable_name[count];
It’s equivalent to the C lines below, as all C arrays decay to a pointer.
Usually used for arrays of contiguous data, invoking this name places a pointer to the start of that memory block onto the stack.
include 'std.stas'
fn main {
reserve variable 8
variable putuln
; putu(nsigned number)ln
}
Probably best expressed in hex, the number printed out is the address of a memory location of 8 bytes allocated on the stack locally to the function.
$ ./stas add.stas -r
4268846
To read the 8 byte value stored at that address I will have to introduce you to stas’s memory keywords.
r8 ; ( address -- value ) | read 1 byte at address and return it
r16 ; ( address -- value ) | read 2 bytes at address and return it
r32 ; ( address -- value ) | read 4 bytes at address and return it
r64 ; ( address -- value ) | read 8 bytes at address and return it
w8 ; ( address value -- ) | treat the as a 1 byte value and write to address
w16 ; ( address value -- ) | treat the as a 2 byte value and write to address
w32 ; ( address value -- ) | treat the as a 4 byte value and write to address
w64 ; ( address value -- ) | treat the as a 8 byte value and write to address
Well, lets use them!
fn main {
reserve variable 8
variable r64 ; never do this!
}
There is one thing too keep in mind.
In stas, function local values in memory are undefined. Never expect them to be any value before writing to them, they could be anything.
Values in stas are always 64 bits, or eight bytes.
If you wanted to store a value from the stack into memory, reserving 8 bytes and using the correct write and read keyword is important to avoid losing information.
$ ./stas add.stas -r
999
include 'std.stas'
fn main {
reserve variable 8
variable 999 w64
variable r64 putuln
}
As you know, you are working with raw pointers here. The compiler cannot help you in avoiding memory exceptions, such as reading from an invalid pointer.
fn main {
0 r64 drop
}
$ ./stas add.stas -r
[1] 2225557 segmentation fault (core dumped) ./stas add.stas -r
It’s a good time to usher in the second type of variable…
An Automatic Variable.
Using automatic variables is where the compiler can help you out, make your life easier for you.
Automatic variables are, automatic. There are many built in keywords for interacting with them. Declaring them is similar to a buffer, the variable type I mentioned before.
auto <variable_name> <count>
The size specified in an auto variable has a different meaning. Instead of being the size in bytes, it’s the number of stas values that can fit inside. All values in the stas stack are unsigned 64 bit integers. So, multiplying the size by eight would give you the actual size in bytes.
fn main {
auto variable 1
}
Auto variables are the most common form of variable, for storing any amount of values from the stack. This means numbers, addresses, indexes, counters, anything. As a programmer, dealing with the raw pointers of variables should be hidden from sight. Automatic variables behave like every other variable in a conventional programming language.
Invoking the name of an auto variable will automatically read it’s value, and places it onto the stack.
Just like before, the value stored inside is undefined.
Best you write to it first…
fn main {
auto variable 1
variable drop
}
Working With Auto Variables.
Stack based language? Push and pop?
Use the pop keyword to write values to the auto variable.
When invoking the pop keyword, the compiler expects an amount of values on the stack equal to the size defined in the declaration.
fn main {
auto var 4
1 2 3 4 pop var
}
fn main {
auto variable 1
99 pop variable
}
This makes auto variables super easy to work with.
include 'std.stas'
fn main {
auto v 1
0 pop v
while v 10 < {
v putu " " puts
v ++ pop v
}
"\n" puts
}
$ ./stas add.stas -r
0 1 2 3 4 5 6 7 8 9
What if you want to expose the address of the variable, like with buffers?
Like the pop keyword, another exists for this purpose.
Although not recomended, pointer arithmetic can be used to access higher values in the variable, just like an array.
fn main {
auto a 2
addr a 91 w64
addr a 8 + 92 w64
}
Constants
Often overlooked, these are extremely useful in all kinds of programs where readablility is important.
A constant variable is one that does not change, at all. Another word for this is immutable, meaning that the value cannot be mutated from it’s original one.
Unlike the other variable types, where it’s inner value must be set seperate to it’s definition, a constant’s inner value must be known at compile time.
Defined with the const keyword, all constant’s store a single value. It is set in it’s definition in an expression evaluated at compile time.
Constants require a different kind of syntax to define it’s value. One where a simple expression can be constructed inside curly braces after it’s name.
fn main {
const v { 5 }
}
include 'std.stas'
fn main {
const a { 10 }
const b { a 15 + }
const c { b 5 / }
a putuln
b putuln
c putuln
}
You haven’t left stas.
It’s separate to the runtime stack, but follows the same principles. It will throw a compiler error on a stack underflow, or if anything other than one value is left on the stack on return.
const a { 5 + } ; uhoh
Anything known at compile time is fair game.
That means all constants can reference other constants, and do arithmetic on them.
$ ./stas add.stas -r
10
25
5
Filling In The Gaps
You can define buffer and automatic variables in other ways than already described.
The normal method is with a single number. Defining the size using a constant or a constant expression is perfectly valid.
const WordSize { 2 4 * }
reserve default_method 8
reserve const_method WordSize
reserve const_expr { 2 4 * }
Another keyword that can be used with variables is the sizeof operator. Prefixed before the name of a variable, it places on the stack the size in bytes of the variable.
reserve Word 1024
const Word[].len { sizeof Word 32 * }
Certain keywords only work on certain variables, here is a chart!
addr pop sizeof
reserve x
auto x x x
const
Global Variables.
Nothing new, global variables can be defined outside of functions and referenced throughout the entire program.
Unlike local variables, you can assume variables defined at the global scope will always be initialised to zero. This is because they are defined in the ‘bss’ section.
auto global 1
fn main {
844 pop global
}
Scoping.
auto v 1
fn main {
auto v 1
{
auto v 1
}
}
fn functor {
auto v 1
}
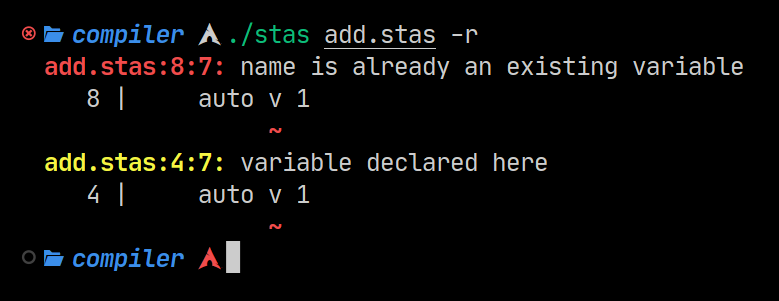
The compiler does not allow duplicate variables, however, this is a legal program.
A scope is the part of the program where a variable is visible and accessible by the programmer.
There are three main scopes, global, function and block.
Nested scopes can overwrite the precedence of other variables in earlier scopes. Think of them as a context. You cannot define duplicate variables in the same context, but can refer to variables lower than your current context.
Global
1auto v 1
2
3fn main {
4 auto v 1
5 {
6 auto v 1
7 }
8}
9
10fn functor {
11 auto v 1
12}Function
1auto v 1
2
3fn main {
4 auto v 1
5 {
6 auto v 1
7 }
8}
9
10fn functor {
11 auto v 1
12}Block
1auto v 1
2
3fn main {
4 auto v 1
5 {
6 auto v 1
7 }
8}
9
10fn functor {
11 auto v 1
12} 1auto v 1
2
3fn main {
4 auto v 1
5 {
6 auto v 1
7 }
8 auto v 1
9}
10
11fn functor {
12 auto v 1
13}With a single alteration, this program raises a compiler error.
Working With Arrays.
; ( array len )
fn print_all_bytes 2 0 {
auto len 1 pop len
auto arr 1 pop arr
}
Start by writing a function for iterating through all of the bytes in an array and printing out it’s values.
It’s best to extract both of the values to variables.
; ( array len )
fn print_all_bytes 2 0 {
auto len 1 pop len
auto arr 1 pop arr
0 while dup len < {
; (idx)
++
} drop
}
Pretty standard while loop, except we aren’t storing and shuffling the length on the stack anymore.
The length is exposed in the inner loop, and incremented every turn.
; ( array len )
fn print_all_bytes 2 0 {
auto len 1 pop len
auto arr 1 pop arr
0 while dup len < {
; (idx)
dup arr +
; (idx *u8)
r8 putu " " puts
; (idx)
++
} drop
"\n" puts
}
Then, use the index in the loop index into the array.
Since it’s a byte array, none of the element sizes will be bigger than one byte. Simply adding the array to get the pointer to the array member will suffice.
Read the member with the read byte operator, then print it’s value. All of the numbers are separated by spaces.
When the loop is done, write a new line.
Now you have a function for printing the bytes in an array, lets write the main function that constructs the array and writes to it…
fn main {
reserve bytes 32
; memset : ( ptr int len -- )
bytes 0 sizeof bytes memset
bytes sizeof bytes print_all_bytes
}
Create an array of bytes with 32 members. Since all variables are undefined, the array must be initialised to zero.
The memset function from the standard library is good for this, like the C function, it fills a block of memory with a constant byte.
The function we created earlier accepts the array, then the length. Expect all the bytes to zero when printed.
include 'std.stas'
fn print_all_bytes 2 0 { ... }
fn main {
reserve bytes 32
; memset : ( ptr int len -- )
bytes 0 sizeof bytes memset
bytes sizeof bytes print_all_bytes
"\n" puts
0
while dup sizeof bytes < {
dup bytes +
; (idx *u8)
over
; (idx *u8 idx)
w8
; (idx)
++
}
drop
bytes sizeof bytes print_all_bytes
}
Time to set the bytes. It’s just like the last array, getting the pointer to the array member is exactly the same.
With the pointer, you can duplicate the index and write it to the array index.
Then, print it.
$ ./stas add.stas -r
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23 24 25 26 27 28
29 30 31
All done!
Working With Strings.
include 'std.stas'
; ( str len )
fn ascii_chars 2 0 {
auto len 1 pop len
auto str 1 pop str
; putc : ( u8 -- ) : print char
0
while dup len < {
dup str + r8 dup
; (idx u8 u8)
"'" puts
putc
"' - " puts
putuln
++
}
drop
}
Strings are very similar to arrays.
When pushing a string onto the stack, two values gets added. The pointer to the start of the string, and it’s length. That means any string could be fed into the function earlier to print all bytes. An alteration to that function is on the left.
fn main {
"Hello!" ascii_chars
}
The putc function prints a singular ascii character to stdout.
You can see in in action on the right!
$ ./a.out
'H' - 72
'e' - 101
'l' - 108
'l' - 108
'o' - 111
'!' - 33
Closing.
The stack has it’s advantages and it’s downsides. I don’t recommend programming using the stack for absolutely everything, variables ease the pain a bit.
As always, I am always open for questions. If the guide wasn’t clear enough, I’ll be there to update it. Want to talk? Github issue or an email.
Goodbye again!