Just In Time For The Most Overengineered Calculator
Intro
stas was great. I want something more.
I am obsessed with making another programming language.
So, I’ve been looking around and learning what’s needed
to do so. Language and compiler design, ASTs,
expressions, all of it.
As an exercise for myself, just to test what I know,
I created a very simple statement based/imperative
programming language. Called tl or
tiny lang it compiles to x86_64 intel
assembly to be compiled with GCC.
“tiny lang”
It’s incredibly simplistic, typeless, and unsafe. In other words, perfect.
The creation of tl and it’s compiler
were used to learn the basics of conventional AST based
compilers. The tl compiler is split into 3
equally small files, the lexer, parser and code
generator.
proc main {
r = 0;
}The simplest program in tl is quite
similar to C.
int main {
return 0;
}You cannot declare any variables, as there are a limited amount of predefined ones.
s0, s1, s2, s3, s4, s5 | Stack variables
a0, a1, a2, a3, a4, a5 | Argument variables
r | Return variableThe stack variables are used to store local values. Use the argument variables to pass values to function calls, expect them to be destroyed on return. The return variable is used to pass return values on return.
All values are computed as unsigned 64 bit numbers, no negatives here.
Since function calls do not return values (they use
the built in return variable), they are not
expressions. So, the call keyword is used
to call a function.
call function; // default call
s0 = function;
call s0; // use exprThere is only one builtin function,
print. It is used to print the value of
one number in a0. Define a function using
the proc keyword, declaring an array of
values is also supported using the data
keyword.
The syntax is similar to C with some alterations.
Only certain complex constructs like while
loops and if/else statements are
supported.
proc addsome {
r = a0 + a1;
}
proc main {
a0 = 10;
a1 = 15;
call addsome;
if r > 20 {
// greater
}
r = 0;
}Index expressions are possible too.
data my_data {
1; 2; 3; 4;
}
proc main {
s0 = 0;
while s0 < 4 {
a0 = my_data[s0];
call print; // print value
s0 = s0 + 1;
}
r = 0;
}Anyway, check it out on Github-right-here
for a better explanation and source code. /examples
here too!
Regardless, it was pretty fun. Turing complete also.
However, this post isn’t about tl.
It’s about jitcalc.
Just In Time.
Okay, I know how to generate expression trees. Forget programming languages, I want to make a calculator.
That’s boring though. I need a twist.
To speed up interpreted languages like lua, JavaScript, C# and the like, most implementations employ Just-In-Time compilation. Instead of the language’s runtime interpreting functions when they are used, they compile it straight down to native machine code during execution.
The fastest language runtimes with a JIT would continuously analyse the program and identify “hot paths” of code where the performance improvement gained from executing a native compilation and it’s overhead compiling it would be quicker than a straight interpretation.
Instead of interpreting an expression passed to the calculator, I want to evaluate the expression by creating a native machine code program at runtime and then execute it.
So the game plan is:
- Read a line from the user.
- Parse it into an expression tree.
- Traverse the expression tree generating native machine code.
- Execute the function generated.
- Print out the return value.
Let’s make a calculator.
String To Tokens
Lexical analysis is a important step that cannot be skipped. It converts all of the word, numbers and special characters into tokens that can be understood by the runtime/calculator.
>>> 10 / 77 + (2 + abc)Collections of characters like + or
2002 should be told apart by the lexer
with each token’s “kind” being the addition operator
and the number 2002.
This lexer has a special property. Whilst showing
the current token parsed in .tok, it
allows the next token in the sequence to looked ahead
to in .peek.
The respective .tok_lit and
.peek_lit are used to display the string
representation of the token in the cases where it’s
kind is a number or an identifier/variable name.
enum Op {
// special
eof uneg
// literals
ident // `abc`
num // `222`
assign obr cbr
add sub mul div mod
}
struct Lexer {
line string
mut:
pos int // line[pos]
tok Op
tok_lit string
peek Op
peek_lit string
}The entire lexer is extremely compact with it’s entire implementation being 55 lines.
fn (mut l Lexer) get() !(Op, string) {
for l.pos < l.line.len {
mut ch := l.line[l.pos]
l.pos++
if ch.is_space() { continue }
mut word := ''
op := match ch {
`+` { Op.add }
`-` { Op.sub }
`*` { Op.mul }
`/` { Op.div }
`%` { Op.mod }
`=` { Op.assign }
`(` { Op.obr }
`)` { Op.cbr }
else {
mut isnum := true
l.pos--
start := l.pos
ch = l.line[l.pos]
if !((ch >= `a` && ch <= `z`) || (ch >= `A` && ch <= `Z`) || (ch >= `0` && ch <= `9`) || ch == `_`) {
return error("Syntax Error: unknown character `${ch.ascii_str()}`")
}
for l.pos < l.line.len {
ch = l.line[l.pos]
if (ch >= `a` && ch <= `z`) || (ch >= `A` && ch <= `Z`) || (ch >= `0` && ch <= `9`) || ch == `_` {
l.pos++
if isnum && !(ch >= `0` && ch <= `9`) {
isnum = false
}
continue
}
break
}
word = l.line[start..l.pos]
if isnum {
Op.num
} else {
Op.ident
}
}
}
return op, word
}
return Op.eof, ''
}
fn (mut l Lexer) next() !Op {
l.tok, l.tok_lit = l.peek, l.peek_lit
l.peek, l.peek_lit = l.get()!
return l.tok
}import readline
fn main() {
mut r := readline.Readline{}
for {
mut l := Lexer {
line: r.read_line(">>> ") or { break }
}
l.next()! // parse next token
if l.peek == .eof {
// zero input tokens, just read again
continue
}
for {
l.next()!
if l.tok == .eof {
break
}
println("${l.tok}\t\t${l.tok_lit}")
}
}
}With some driver code, lexical analysis works like a charm.
>>> hello = 10 + 2 / 10 - abc
ident hello
assign
num 10
add
num 2
div
num 10
sub
ident abcTokens To Math Expression
Abstract Syntax Tree, or AST, is a tree representation of the syntactic structure of a target programming language. It’s an incredibly invaluable data structure in compilers.
Forget the jargon, it makes sense when you see how it’s used and created.
With each expression below, they generate an expression tree with respect for each operations order.
4 + 2 * 10 + 12 +
/ \
12 +
/ \
4 *
/ \
2 10
10 * (2 + 8) + 3 +
/ \
3 *
/ \
10 +
/ \
2 8a = -(10 + 2) =
/ \
a -u
/
+
/ \
10 2Each node inside the expression tree has two sides, a left and right hand side. It also contains the nodes type and it’s literal value if needed.
struct Expr {
lhs &Expr = unsafe { nil }
rhs &Expr = unsafe { nil }
op Op
val string
}In a V version coming soon, expect recursive structs with Option types. For now though, nullable pointers are perfectly fine.
lhs ?&Expr // if lhs := node.lhs { }
rhs ?&Expr // if rhs := node.rhs { }Pratt Parsing
Writing a handmade expression parser from scratch, abiding by operator precedence, was something I had to learn myself. I stumbled upon a technique called Pratt parsing. This article, Simple but Powerful Pratt Parsing by maklad, was extremely helpful at outlining it’s structure.
I then came across another implementation of a Pratt
parser in the V compiler source code, expr.v.
The entire expression parser is implemented in 61 lines.
Calling the expr() function once will
return the root node the parsed expression tree. It
supports bailing out and returning a syntax error as it
appears.
fn expr(mut l Lexer, min_bp int) !&Expr {
l.next()!
mut lhs := match l.tok {
.num, .ident {
&Expr{op: l.tok, val: l.tok_lit}
}
.obr {
o_lhs := expr(mut l, 0)!
if l.next()! != .cbr {
return error("Syntax Error: expected closing brace")
}
o_lhs
}
else {
match l.tok {
.sub {
r_bp := 7
&Expr{
rhs: expr(mut l, r_bp)!,
op: .uneg
}
}
else {
return error("Syntax Error: expected identifier or number")
}
}
}
}
for {
if l.peek in [.eof, .obr, .cbr] {
break
}
l_bp, r_bp := match l.peek {
.assign {
if lhs.op != .ident {
return error("Syntax Error: cannot assign to a value literal")
}
2, 1
}
.add, .sub { 3, 4 }
.mul, .div, .mod { 5, 6 }
else {
return error("Syntax Error: expected operator after value literal")
}
}
if l_bp < min_bp {
break
}
l.next()!
op := l.tok
lhs = &Expr{
lhs: lhs,
rhs: expr(mut l, r_bp)!,
op: op
}
}
return lhs
}The Easy Way Out
Now that you have an expression tree, what you do with it is your problem.
Write a recursive evaluator? Print the tree out? Generate code? Anything.
For reference, I have created a function to evaluate the tree recursively.
It starts at the root node and recursively calls
eval() on it’s children. It also supports
assignment expressions with a symbol table passed
alongside the current node.
>>> 2 + 2 * -5
-8
>>> a = 10 / 2
>>> a
5fn eval(node &Expr, mut symtable map[string]i64) i64 {
return match node.op {
.ident { symtable[node.val] }
.num { node.val.i64() }
.uneg { -eval(node.rhs, mut symtable) }
.add { eval(node.lhs, mut symtable) + eval(node.rhs, mut symtable) }
.sub { eval(node.lhs, mut symtable) - eval(node.rhs, mut symtable) }
.mul { eval(node.lhs, mut symtable) * eval(node.rhs, mut symtable) }
.div { eval(node.lhs, mut symtable) / eval(node.rhs, mut symtable) }
.mod { eval(node.lhs, mut symtable) % eval(node.rhs, mut symtable) }
.assign {
symtable[node.lhs.val] = eval(node.rhs, mut symtable)
symtable[node.lhs.val]
}
else { panic("unreachable") }
}
}
fn main() {
mut r := readline.Readline{}
mut symtable := map[string]i64
for {
mut l := Lexer {
line: r.read_line(">>> ") or { break }
}
l.next()!
if l.peek == .eof {
continue
}
root := expr(mut l, 0) or {
println(term.fail_message(err.str()))
continue
}
v := eval(root, mut symtable)
if root.op != .assign {
println(v)
}
}
}fn march(node &Expr, dep int) {
if isnil(node) {
return
}
if dep != 0 {
c := dep - 1
print("${` `.repeat(c * 3)}└─ ")
}
match node.op {
.num, .ident { println("`${node.val}`") }
else { println(node.op) }
}
march(node.lhs, dep + 1)
march(node.rhs, dep + 1)
}root := expr(mut l, 0) or {
println(term.fail_message(err.str()))
continue
}
march(root, 0)I also implemented a function to print out the tree recursively starting at the root.
>>> 2 + 2 * -5
add
└─ `2`
└─ mul
└─ `2`
└─ uneg
└─ `5`
>>> 10 + 50 / 2
add
└─ `10`
└─ div
└─ `50`
└─ `2`Generating Native Machine Code
I’ve created a basic API to aid in generating native machine code functions at runtime.
create_program()
.comment()
.reset()
.finalise()
.hexdump()
.ret()
.write64()
.mov64_rax()
.mov64_rcx()
These are just base functions, they don’t do any complex opcodes. You are meant to implement higher level ones yourself.
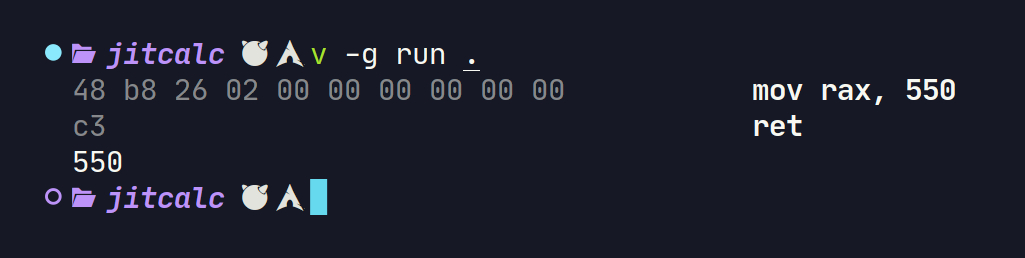
fn main() {
mut prg := create_program()
prg.mov64_rax(550)
prg.ret()
prg.hexdump()
function := prg.finalise()
println(function())
}
W^X (write xor execute)
Each function does a lot of work behind the scenes to ensure proper code execution.
Allocating memory with a plain C
malloc() and then trying to execute code
inside that is simply not possible.
The instruction pointer residing in any part of that memory will cause a segfault. Why?
All memory addresses handed out by the kernel are part of virtual memory mapped pages with their own fine grained permissions. All memory handed out by default memory allocators usually do not ask the kernel for memory with a permission to execute code within, it’s a security risk if they do.
Even if allocators did, they would be stopped dead in their tracks.
All serious operating system kernels implement
something called W^X or write xor
execute. It is a security feature where every
single page of memory avaliable to a program can be
either writable or executable, but not both. Without
W^X, a program can write CPU instructions
in an area of memory usually for data then run those
instructions. It’s especially dangerous if the writer
of memory is a malicious actor.
Two problems to solve: How do we allocate a page of memory to store instructions in, then make it executable?
C Territory
V does not provide a built in method for low level
control over raw pointers of memory. You must step into
C to do it yourself. Luckily, V’s C interop is
effortless. Use the mmap(2) and
mprotect(2) C functions to do this.
#include <sys/mman.h>
#include <unistd.h>
fn C.sysconf(name int) i64
fn C.mmap(base voidptr, len usize, prot int, flags int, fd int, offset i64) voidptr
fn C.munmap(ptr voidptr, size usize) int
fn C.mprotect(addr voidptr, len usize, prot int) int
// create a JitProgram struct and allocate suitable pages
fn create_program() JitProgram {
// `len` variable contains the CPU dependent size of a memory page in bytes.
len := C.sysconf(C._SC_PAGESIZE)
if len == -1 {
panic("create_program: sysconf() failed")
}
// allocate zeroed memory with read and write access
ptr := C.mmap(0, len, C.PROT_READ | C.PROT_WRITE, C.MAP_ANONYMOUS | C.MAP_PRIVATE, -1, 0)
if ptr == -1 {
panic("create_program: mmap() failed")
}
// manually and unsafely create a fixed u8 array using the special memory page
code := unsafe {
array {
element_size: 1
data: ptr
cap: int(len)
// The array flags `.nogrow` and `.nofree` were added to V by me.
// I realised the need for truly static arrays, and implemented them in a PR.
// PR: https://github.com/vlang/v/pull/16661
flags: .noshrink | .nogrow | .nofree
}
}
return JitProgram {
code: code
}
}
type JitProgramTyp = fn () i64
// return a function pointer with the code generated
fn (mut p JitProgram) finalise() JitProgramTyp {
// play by W^X's rules and change the current memory protection of the pages to read and execute
if C.mprotect(p.code.data, p.code.cap, C.PROT_READ | C.PROT_EXEC) != 0 {
panic("JitProgram.finalise: mprotect() failed")
}
return unsafe { JitProgramTyp(p.code.data) }
}What You Came For
Time for the hard part. Generating machine code.
This style of code generation is inspired by
tl, which in turn I obtained inspiration
from the V native backend.
After you call the gen() function it
will generate code leaving the result of it’s tree
expression inside rax register. The left
and right hand sides of nodes can be easily chained
together to create decent code with little complexity
in code generation.
The gen() function goes like this for a
basic infix expression such as
expr + expr.
gen(node.rhs), value of the right side resides in theraxregister.push rax, storing the value of the right hand side on the stack.gen(node.lhs), value of the left side then in theraxregister.pop rcx, storing the saved value of the right hand side in rcx.The left hand side now resides in
raxand the right,rcx.add rax, rcx, performing the operation and leaving the resulting value inraxlike agen()call should.
Even if you don’t get it initially, just press on.
Symtable
The function generated should be able to access the symbol table containing all of the variables, it can do this with raw pointers.
Inside V though, you cannot get the address of a map value, they must be boxed.
struct Box[T] {
v T
}
// type Symtable = map[string]i64
type Symtable = map[string]&Box[i64]Codegen
Just like the eval() function,
gen() will take a similar recursive
route.
This is the skeleton implementation for the
gen() function.
It first handles leaf operations like a literal number or variable name, and the assignment operator.
If it doesn’t match any of the above, it then
generates code for both the left and right sides
keeping them in rax and rcx
respectively. Then it will handle math operations,
leaving the result in rax. The
gen() function can continue recursing,
leaving the result of each expression in the tree in
rax. This is what glues it all together
and leaves code generation for a register machine like
x86_64 incredibly simple.
fn gen(node &Expr, mut prg JitProgram, mut symtable Symtable)! {
match node.op {
.num, .ident, .assign {
panic("unimplemented")
return
}
else {}
}
gen(node.rhs, mut prg, mut symtable)!
// expr in `rax`
if node.op == .uneg {
panic("unimplemented")
}
prg.comment('push rax')
prg.code << 0x50
gen(node.lhs, mut prg, mut symtable)!
// expr in `rax`
prg.comment('pop rcx')
prg.code << 0x59
// left hand side in `rax` and right hand side in `rcx`
// handle infix operation with `op rax, rcx`
match node.op {
.add, .sub, .mul, .div, .mod {
panic("unimplemented")
}
else {
panic("unreachable")
}
}
// ending `gen()` with result in `rax`
}Implementing The Rest
Together, lets implement the rest of the code.
You should know a decent amount of x86_64 assembly, don’t worry about the bytecode.
I use nasm and ndisasm to
extract the bytecode of x86_64
assembly instructions.
bits 64
add rax, rcx
sub rax, rcx
imul rax, rcx
mov rax, 0xDEADBEEF$ nasm f.asm -o f -O0 && ndisasm f -b 64
00000000 4801C8 add rax,rcx
00000003 4829C8 sub rax,rcx
00000006 480FAFC1 imul rax,rcx
0000000A B8EFBEADDE mov eax,0xdeadbeef
Then, I just copied and pasted the bytes as needed…
match node.op {
.add {
prg.comment('add rax, rcx')
prg.code << [u8(0x48), 0x01, 0xC8]
}
.sub {
prg.comment('sub rax, rcx')
prg.code << [u8(0x48), 0x29, 0xC8]
}
.mul {
prg.comment('imul rax, rcx')
prg.code << [u8(0x48), 0x0F, 0xAF, 0xC1]
}
.div, .mod {
prg.comment('cqo')
prg.code << [u8(0x48), 0x99]
prg.comment('idiv rcx')
prg.code << [u8(0x48), 0xF7, 0xF9]
if node.op == .mod {
prg.comment('mov rax, rdx')
prg.code << [u8(0x48), 0x89, 0xD0]
}
}
else {
panic("unreachable")
}
}if node.op == .uneg {
prg.comment('neg rax')
prg.code << [u8(0x48), 0xF7, 0xD8]
return
}Implementing value literals like integers and variables aren’t too hard either.
For variables, I simply move the address of the
enclosed value to the rax register, then
dereference it.
The assign operator is similar. The right hand side of the equals sign contains the expression, and the left, the variable name.
The right hand side is generated, with the
expression’s result in rax. Then the
variable’s address is moved into rcx, with
rax finally being written to it’s
location.
See both in action below…
match node.op {
.num {
prg.mov64_rax(node.val.i64())
return
}
.assign {
gen(node.rhs, mut prg, mut symtable)!
if node.lhs.val !in symtable {
symtable[node.lhs.val] = &Box[i64]{}
}
prg.mov64_rcx(voidptr(&symtable[node.lhs.val].v))
prg.comments.last().comment = 'mov rcx, &${node.lhs.val}'
prg.comment('mov [rcx], rax')
prg.code << [u8(0x48), 0x89, 0x01]
return
}
.ident {
if node.val !in symtable {
return error("Gen: identifier `${node.val}` not defined")
}
prg.mov64_rax(voidptr(&symtable[node.val].v))
prg.comments.last().comment = 'mov rax, &${node.val}'
prg.comment("mov rax, [rax]")
prg.code << [u8(0x48), 0x8B, 0x00]
return
}
else {}
}Done
That is it, I mean it.
You now have a simple, unoptimised and robust code generator for a basic calculator AST.
Let’s wrap it up by updating the driver code…
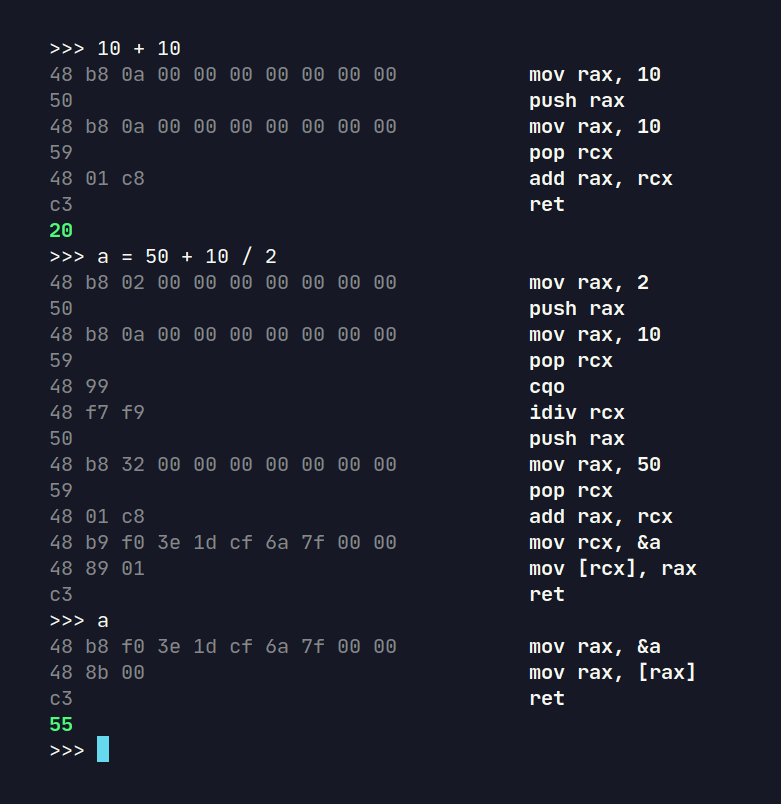
fn main() {
mut r := readline.Readline{}
mut symtable := map[string]i64
for {
mut l := Lexer {
line: r.read_line(">>> ") or { break }
}
l.next()!
if l.peek == .eof {
continue
}
root := expr(mut l, 0) or {
println(term.fail_message(err.str()))
continue
}
if l.peek != .eof {
println(term.fail_message("Syntax Error: trailing tokens after expression"))
continue
}
gen(root, mut prg, mut symtable) or {
println(term.fail_message(err.str()))
prg.reset()
continue
}
prg.ret()
prg.hexdump()
fnptr := prg.finalise()
value := fnptr()
if root.op != .assign {
println("${term.bold(term.green(value.str()))}")
}
prg.reset()
}
}Goodbye
Techniques like ASTs, parsers, JITs, and others aren’t new. Far from it actually. However, I find them very very interesting. It’s only a matter of time before I do some experimentation here and there.
As always, source code is always avaliable and preferred to copy pasting from here anyway.
New website, new blog, new style, new everything. Happy new year!
TY for coming in. cya!