Learning By Doing In C Part 1 - Creating My Own malloc()
High level languages often abstract concepts like dynamic arrays, strings, hash tables, memory allocation, everything. Modern languages just leave developers spoiled, how are people going to learn if they don’t even know how these work under the hood? That’s what I think at least.
It’s time to go back to the basics, in C!
Today, I am going to be walking you through my malloc() implementation. Unlike the stack, where you have access to about 8MB of space for local function variables, memory taken from the heap always stays in scope and can be as big as the ram sticks in your computer allow.
To talk about how to give memory, we first have to talk about where is comes from.
Where does memory come from?
In short, the operating system kernel. The kernel is responsible for many functions and handing out memory to programs is just one of them.
I’ll talk about one of the Linux kernel’s system calls used to map memory for a process. The mmap system call.
void *mmap(void *addr, size_t len, int prot, int flags, int fildes, off_t off);
Short for “memory map”, it allows the process to return a pointer to mapped pages of memory. What’s a page? It’s CPU architecture dependent. On x86_64/amd64, the CPU architecture used by most systems today, it is 4096 bytes. A multiple of this number must be passed into the 2nd argument of the system call.
This is generally how the system call is used in my allocator, the only thing that varies is the size.
mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
The first argument essentially hints to the kernel to where that memory ends up, if it cannot be placed there, a close address will be allocated. Passing a null pointer tells the kernel that the process does not care where it ends up.
The third and forth arguments are a bit different as they are both bitfields. Specifying PROT_READ and PROT_WRITE both mean the memory is allowed to be read and written to. If PROT_READ was specified and PROT_WRITE was not, writing to the memory will result in a segmentation fault. Even a permission of PROT_EXEC can be passed in allowing CPU instructions inside that memory to be executed.
On the forth argument, if MAP_PRIVATE is specified, modifications to the mapped data by the process will be visible only to the calling process. MAP_ANONYMOUS means that the memory is anonymous and ensures it comes back to this process and is not mapped to a file.
The second last argument is a file descriptor. One use that mmap allows, is to open a file in the filesystem and map it in some address space to allow editing based on address space instead of write() operations.
Take a look at this example below.
fildes = open(...);
address = mmap(NULL, filesize, PROT_READ, MAP_PRIVATE, fildes, 0);
It first opens a file and return it’s file descriptor. It then passes it to the mmap system call along with its size. The resulting address space’s permissions allow it to only be read. I pass in a value of negative one as the file descriptor, this tells the kernel that this is not mapping any file.
I hope I explained mmap well. It’s used as the primary way to attain memory from the kernel to then later be handed out by the malloc() function in user space, without talking to the kernel.
Because that is the bottleneck here, the kernel.
The whole point of the malloc function is to be an efficient abstraction layer over interactions with kernel.
Think of malloc like a manager of a store. Talking to the supplier when they need more stock in bulk and then later use this bulk product for handing out to a customers when they come, restocking by talking to to the suppliers as needed. The customers have the luxury of fast access without the slow process of contacting the suppliers themselves, every single time they need it.
I mean, why allocate a page size (4096) of bytes with mmap for just the 39 bytes your program might need? Wouldn’t it be nice to allocate a page first, then hand out that memory when your program requests it?
Easy on paper, complicated in practice.
- How do you even keep track of memory you hand out?
- How can you ensure there is always memory to hand out?
- Can this pool of memory grow?
- How do you reuse memory blocks in the event it is free()d?
Data structures, data structures, data structures… linked list! A pretty uncommon datatype. A linked list is a linear data structure, in which the elements are not stored at contiguous memory locations. Check out this image from tutorialspoint:
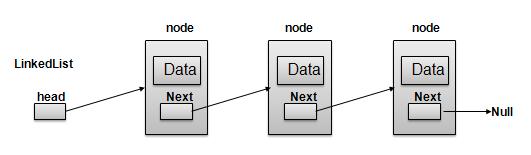
Collections of data are stored in nodes/blocks, with a pointer that points to the next block in the sequence. This datatype is often used in memory allocators, a kind of freeform array where chained items can be reordered at will.
On the right, was a pretty primitive memory header used in a hobby operating system. When allocating a block of memory, store a header right before this block of memory pointing to the next block in the sequence along with it’s size.
struct Header {
size_t size;
bool used;
void *next;
}
NEXT ─────────────────────────────┐ NEXT ─────────────────┐ NEXT ─────────────────
+--------+-------------------------+--------+--------------+--------+--------------+
+ HEADER | MEMORY BLOCK | HEADER | MEMORY BLOCK | HEADER | MEMORY BLOCK |
+--------+-------------------------+--------+--------------+--------+--------------+
After getting enough memory in to fit in the header and the size requested, you can return a pointer to the memory after the header to the user. When getting the pointer back to have the memory freed, just subtract the size of the header to get a pointer to the header containing all the metadata of the allocated block.
void *malloc(size_t size){
// ...
return &header + sizeof(Header);
}
void free(void *ptr){
Header *h = ptr - sizeof(Header);
// ...
}
There’s a glaring issue with the above header. The memory footprint. Why ask for 8 bytes when an entire 24 header gets added on top? Obviously 8 + 1 + 8 does not equal 24, what’s going on here?
Struct padding. A concept in many languages automatically done by the compiler that adds the one or more empty bytes between the memory addresses to align the data in memory. Allign the data to what?
sizeof(size_t) == 8
sizeof(bool) == 1
sizeof(void *) == 8
sizeof(struct Header) == 24 // WTF??
Modern 64 bit CPUs read memory in 64 bits, anything less is slower. When encountering a value on the boundary between two 8 byte chunks, two reads are performed, one on the higher chunk and one on the lower with some bit shifting to join them together. Struct padding is a necessary evil to allow fast reads.
I tried a different tactic…
Fixed Size Allocation
Fixed size allocation has multiple advantages, you always know the size of blocks and the memory is basically impervious to fragmentation. Fixed size allocation also reduces a block header’s footprint to essentially zero.
My allocator works with pools of memory at sizes 16, 32, 64, 128, 512 and 1024 bytes. Here is some sections of the allocator below.
static void lallocator_init(size_t each_arena_size){
lpool_allocator_init(&alloc_ctx.pools[0], each_arena_size, 16);
lpool_allocator_init(&alloc_ctx.pools[1], each_arena_size, 32);
lpool_allocator_init(&alloc_ctx.pools[2], each_arena_size, 64);
lpool_allocator_init(&alloc_ctx.pools[3], each_arena_size, 128);
lpool_allocator_init(&alloc_ctx.pools[4], each_arena_size, 512);
lpool_allocator_init(&alloc_ctx.pools[5], each_arena_size, 1024);
MSG("--- initialised 6 allocation pools ---",0);
}
When allocating memory, check its size to ascertain what memory pool it should reside in. Then call it’s own malloc function.
#ifdef _LMALLOC_EXPORT_MALLOC
#define MALLOC_FN malloc
#else
#define MALLOC_FN __lmalloc
#endif
void *MALLOC_FN(size_t size){
if (size == 0) {
MSG("called with size 0!",0);
return NULL;
}
if (size <= 16) {
return lpool_malloc(&alloc_ctx.pools[0]);
} else if (size <= 32) {
return lpool_malloc(&alloc_ctx.pools[1]);
} else if (size <= 64) {
return lpool_malloc(&alloc_ctx.pools[2]);
} else if (size <= 128) {
return lpool_malloc(&alloc_ctx.pools[3]);
} else if (size <= 512) {
return lpool_malloc(&alloc_ctx.pools[4]);
} else if (size <= 1024) {
return lpool_malloc(&alloc_ctx.pools[5]);
} else {
return lmemmap_malloc(size);
}
}
This is all very simple, but how do the “headers” work now?
The Free List
Take a strip of fixed size blocks, they are either used or unused. How do you tell if a block is used or unused? The memory pool has an internal pointer that points to the root block in a linked list of only freed blocks.
+----------------+----------------+----------------+----------------+----------------+
+ USED BLOCK | FREE BLOCK | FREE BLOCK | USED BLOCK | FREE BLOCK |
+----------------+----------------+----------------+----------------+----------------+
All that wasted space inside freed memory blocks, how can we put it to use? We know if blocks are used or unused and their sizes. That leaves only one thing, a pointer to the next block. Instead of creating a header, how about storing that pointer inside the start of free blocks?
All freed blocks contain a pointer to the next freed block, they would all link up like this.
mem.free ──────────┐
│ ┌─────────────────────────────────┐
│ ┌────────────────┼────────────────────┐ │
+----------------+----------------+----------------+----------------+----------------+
+ USED BLOCK | FREE BLOCK | FREE BLOCK | USED BLOCK | FREE BLOCK |
+----------------+----------------+----------------+----------------+----------------+
│
────────────────────────────────────┘
Want to give out a block? Simply pop off the head of the list and make the new free root point to the location stored in the orginal list root. Both free and malloc add and remove from the head of the linked list, respectively.
mem.free ─────────────────────────────────────────────────────────────┐
┌────────────────────┼────────────┐
│ │ │
+----------------+----------------+----------------+----------------+----------------+
+ USED BLOCK | <USED BLOCK> | FREE BLOCK | USED BLOCK | FREE BLOCK |
+----------------+----------------+----------------+----------------+----------------+
│
────────────────────────────────────┘
mem.free ────────────────────────────────────────┐
│
│
+----------------+----------------+----------------+----------------+----------------+
+ USED BLOCK | USED BLOCK | FREE BLOCK | USED BLOCK | <USED BLOCK> |
+----------------+----------------+----------------+----------------+----------------+
│
────────────────────────────────────┘
They want to free a block? Link up the list again. The free root now points to the chunk to free, and the address stored at the chunk to free point to the old free root. Easy!
mem.free ──────────┐
│
│ ┌───────┐
+----------------+----------------+----------------+----------------+----------------+
+ USED BLOCK | <FREE BLOCK> | FREE BLOCK | USED BLOCK | USED BLOCK |
+----------------+----------------+----------------+----------------+----------------+
│
────────────────────────────────────┘
mem.free ────────────────────────────────────────────────────────────────────────┐
┌────────────────────────────────────────────────────┐ │
│ ┌───────┐ │ │
+----------------+----------------+----------------+----------------+----------------+
+ USED BLOCK | FREE BLOCK | FREE BLOCK | USED BLOCK | <FREE BLOCK> |
+----------------+----------------+----------------+----------------+----------------+
│
────────────────────────────────────┘
All operations should remain O(1) (constant time), with basically zero cost to memory!
The lmalloc Allocator
After all that, I’m ready to talk about the allocator. It comes to around 300 lines, 400 lines with comments. I made an effort to write comments in the source code of the allocator to document it as closely as possible. This is to help readers follow along as the actual allocator is quite simple!
All memory arenas are, is just large strips of memory that all blocks reside in. When allocating, if free blocks are avaliable in the linked list, use them. If not, the arena works as a simple bump allocator.
The ’next’ field? Memory arenas can eventually run out, they are not infinite. In the case that an arena is filled (when the base reaches the top), a new arena is allocated and a chain of arenas starts.
typedef struct mem_arena mem_arena;
struct mem_arena {
void *memory_arena_base;
void *memory_arena_top;
mem_arena* next;
};
Here is an example allocator structure after extensive use. As you can see, memory pools for block sizes 16, 64 and 1024 have exeeded their root arenas and more arenas needed to be allocated with a memory map.
allocator_context
├ pool_context (16)
│ └ mem_arena
│ └ mem_arena
│
├ pool_context (32)
│ └ mem_arena
│
├ pool_context (64)
│ └ mem_arena
│ └ mem_arena
│ └ mem_arena
│
├ pool_context (128)
│ └ mem_arena
│
├ pool_context (512)
│ └ mem_arena
│
└ pool_context (1024)
└ mem_arena
└ mem_arena
typedef struct {
pool_context pools[6];
} allocator_context;
The allocator context is a struct containing an array of 6 pool contexts.
typedef struct {
mem_arena* arena;
uint16_t memory_block_size;
size_t arena_size;
void **last_free;
} pool_context;
A pool context is what we’ve talked about before. Containing a pointer to the root block in the free list, a memory arena containing all of the blocks and future blocks, the size of that arena and the fixed sizes of every block.
This is the allocate and free functions on a pool taken from the lmalloc source code, containing annotations.
// Allocate memory in a pool's arena, either by returning free blocks or making
// space in the arena.
static void *lpool_malloc(pool_context *memctx){
void *memloc;
// No freed blocks to fill, allocate a new block.
if (memctx->last_free == NULL){
// Make sure there is avaliable space in the arena, if not, allocate
// a new one.
lpool_check_size(memctx);
// Simple bump allocator.
memloc = memctx->arena->memory_arena_base;
memctx->arena->memory_arena_base += memctx->memory_block_size;
MSG("new %u byte block allocated",memctx->memory_block_size);
return memloc;
}
// Free blocks avaliable!
// Remove the head of the linked list of free chunks.
memloc = memctx->last_free;
memctx->last_free = *memctx->last_free;
MSG("returned old freed %u byte block",memctx->memory_block_size);
return memloc;
}
// Free memory in a pool's arena.
static void lpool_free(pool_context *memctx, void * loc){
if (memctx->last_free == NULL){
// First freed chunk in the list.
memctx->last_free = loc;
*memctx->last_free = NULL;
MSG("freed first free %u byte block since full alloc",
memctx->memory_block_size);
} else {
// Reorder the linked list by adding to the head of the linked list
// of free chunks. Make the memory address passed in contain a pointer
// that points to the last freed chunk. The memory address now becomes
// the last freed chunk.
*((void**)loc) = memctx->last_free;
memctx->last_free = loc;
MSG("freed %u byte block",memctx->memory_block_size);
}
}
Practical lmalloc Examples
I just had to hook this up to V and test it out, check out this makefile below. The default target ’time’ requires the target ‘obj’ and so builds the lmalloc object file, exporting the malloc and free functions without their prefixes. The ’time’ target then compiles two V executables with the autofree engine and with no garbage collector, with one containing the lmalloc functions. It then used hyperfine to time the results.
.PHONY: time
time: obj
v -g -autofree -gc none test.v -o main-malloc
v -g -autofree -gc none test.v -o main-lmalloc \
-cflags "$(shell pwd)/lmalloc.o"
hyperfine './main-lmalloc' './main-malloc' -N --warmup 20
.PHONY: obj
obj:
gcc -ggdb -O3 -c lmalloc.c -o lmalloc.o \
-D _LMALLOC_EXPORT_MALLOC
The file ’test.v’ contains a thousand lines of unit tests for strings and string manipulation, since I know that everything to do with strings call malloc this would be a pretty good test.
The results? 10% to 20% increase in speed. Not incredible time, but pretty good for my first try at beating out libc at it’s own job.
The End?
I’m really happy with the outcome of my allocator, expect for more high level concepts in the forthcoming posts! I’d say I’ll continue this series for about 5 posts, then I’ll get right back to stas.
Until then, Goodbye!