Learning By Doing In C Part 2 - Lossless compression And "Modern" Strings
Preface
You know, I really thought I could get away with a quick double release. Write up a bit on dynamic strings, throw compression in there and be done in a couple days.
I was wrong.
But I did learn a couple lessons which could all be boiled down to just thinking about the code you write. A little extra knowledge also helped finding this horrible bug. All memory corruption bugs are just the worst to deal with as no amount of static analysis, compiler sanitisers and debuggers will be of any help.
Anyway, rant over. Time to fix the most annoying part of C …
The Tumor That Is Null Terminated Strings
Like a tumor, once it’s in there, you’re going to have a hard time ripping it out.
Null terminated strings came into being due to the limited memory of older machines 5 decades ago. It solved the problem of having a way to store a string’s length with minimal size overhead.
They had two options, prepending the length of the string before the data, …
0x00 0x0C `H` `e` `l` `l` `o` `_` `w` `o` `r` `l` `d` `!`
… or a byte of 0 (null terminator) at the end signifying the end of the string.
`H` `e` `l` `l` `o` `_` `w` `o` `r` `l` `d` `!` 0x00
See how I use two bytes at the start of the first example, a 16 bit number. Assuming it would be unsigned, that’s a maximum length of 65535. Some even considered the use of a 1 byte number, with a 255 maximum length. Null terminated strings worked perfectly for any size, so it was the best option for it’s time.
That’s the thing, it was the best option for it’s time.
Null terminated strings have caused thousands of security problems for all programs in C. C’s standard library is also horrible with dealing with strings, it’s simply never evolved. Null terminated strings have engrained itself inside all C APIs, infecting literally every part of the standard library.
Don’t get me wrong, C is still amazing, but the way it handles strings holds it back from really growing as a language.
A string implementation should get the best of both worlds. Storing a length and also including a null terminator for interfacing with C APIs. Infact, this is what V does under the hood too.
Dynamic Strings
typedef struct {
char *cstr;
uint32_t len;
int is_literal;
} string;
#define slit(s) (string){(char *)s, sizeof(s)-1, 1}
This is our dynamic string. A simple struct passed around by value, no pointer complexity here. The inspiration for the extremely helpful macro and the ‘is_literal’ field were from V, I assume this is nothing new though. Since these are dynamic strings, the use of dynamic memory mallocation will be used. You can’t free string literals so the field is used to distinguish between them, and guard against double frees.
No matter how much smaller I make the fields, due to struct padding it will never be less that 16 bytes as you need to store a pointer (8 bytes) and some kind of length information. I have the memory to spare, a pointers worth of overhead is nothing.
Here are the functions I’ve built up to deal with them.
void string_free(string *a);
string string_concat(string a, string b);
bool string_contains(string str, string substr);
bool string_equals(string a, string b);
string string_trim_all_whitespace(string a);
Here are some examples below!
string hello = slit("Hello");
hello = string_concat(hello, slit(" world!\n"));
// join strings together
printf("%s", hello.cstr);
// print null terminated represention
// 'Hello world!\n'
if (string_contains(hello, slit("world"))){
puts("string contains the substring 'world'");
}
if (string_equals(hello, slit("Hello world!\n"))){
puts("string equals the string 'Hello world!\\n'");
}
string whsp_gone = string_trim_all_whitespace(slit("\n hello\n "));
// trim all whitespace, this includes newlines, spaces and tab characters
printf("whitespace trim '%s'\n", whsp_gone.cstr);
// 'hello'
string_free(&whsp_gone);
string_free(hello);
// free unused strings
Interfacing with C APIs that require null terminated strings can be used at any time and is perfectly seamless and can be opted into at any time, no conversion necessary.
write_files(slit("text.txt"));
void write_files(string file_name){
FILE *f1 = fopen(string_concat(file_name, slit(".raw")).cstr, "w");
FILE *f2 = fopen(string_concat(file_name, slit(".key")).cstr, "w");
}
typedef struct {
char *data;
uint32_t len;
uint32_t cap;
} str_builder;
I also introducted string builders, another idea from V. Basically a dynamic array or buffer that makes multiple concatenations less expensive with all of those malloc calls.
It works by keeping an internal length and capacity. Appending to the string builder will increase it’s internal length, if it is bigger than what the buffer can hold by comparing against the capacity field, double it’s capacity and reallocate the entire array.
This is all checked for in the ’ensure_cap’ function.
void builder_ensure_cap(str_builder *builder, uint32_t len){
if (builder->len + len > builder->cap) {
builder->cap *= 2;
if (builder->cap < builder->len + len)
builder->cap = builder->len + len;
builder->data = realloc(builder->data, builder->cap);
MSG("additional %u bytes (new cap: %u)",len, builder->cap);
}
}
The append function is just a simple memcpy for both dynamic strings and C strings, the ’ensure_cap’ function guards against buffer overflows.
Well, that was easy? If only all modern languages acted this way … oh wait, they do. I mean even C++ was quick to implement a string datatype, their standard library is in shambles anyway.
Well, with all of that out of the way, I wanted to try something harder. Lossless file compression has always gotten me interested, Huffman Coding is no exception. It’s a really cool algorithm when you really think about it, let me explain…
Huffman Coding
Huffman Coding is a way to encode characters or bytes using fewer bits than their full representation based on their occurrence in a file.
For example a character like ‘E’ would take less bits to encode than a letter like ‘X’ because ‘E’ appears in a text a lot more often than ‘X’. This is the basis for Huffman Coding.
bits \wo encoding | 288
bits \w encoding | 135
bits saved | 153
| 53% bits saved!
Character | Frequency | Encoding
-----------+-----------+----------
space | 7 | 111
a | 4 | 010
e | 4 | 000
f | 3 | 1101
h | 2 | 1010
i | 2 | 1000
m | 2 | 0111
n | 2 | 0010
s | 2 | 1011
t | 2 | 0110
l | 1 | 11001
o | 1 | 00110
p | 1 | 10011
r | 1 | 11000
u | 1 | 00111
x | 1 | 10010
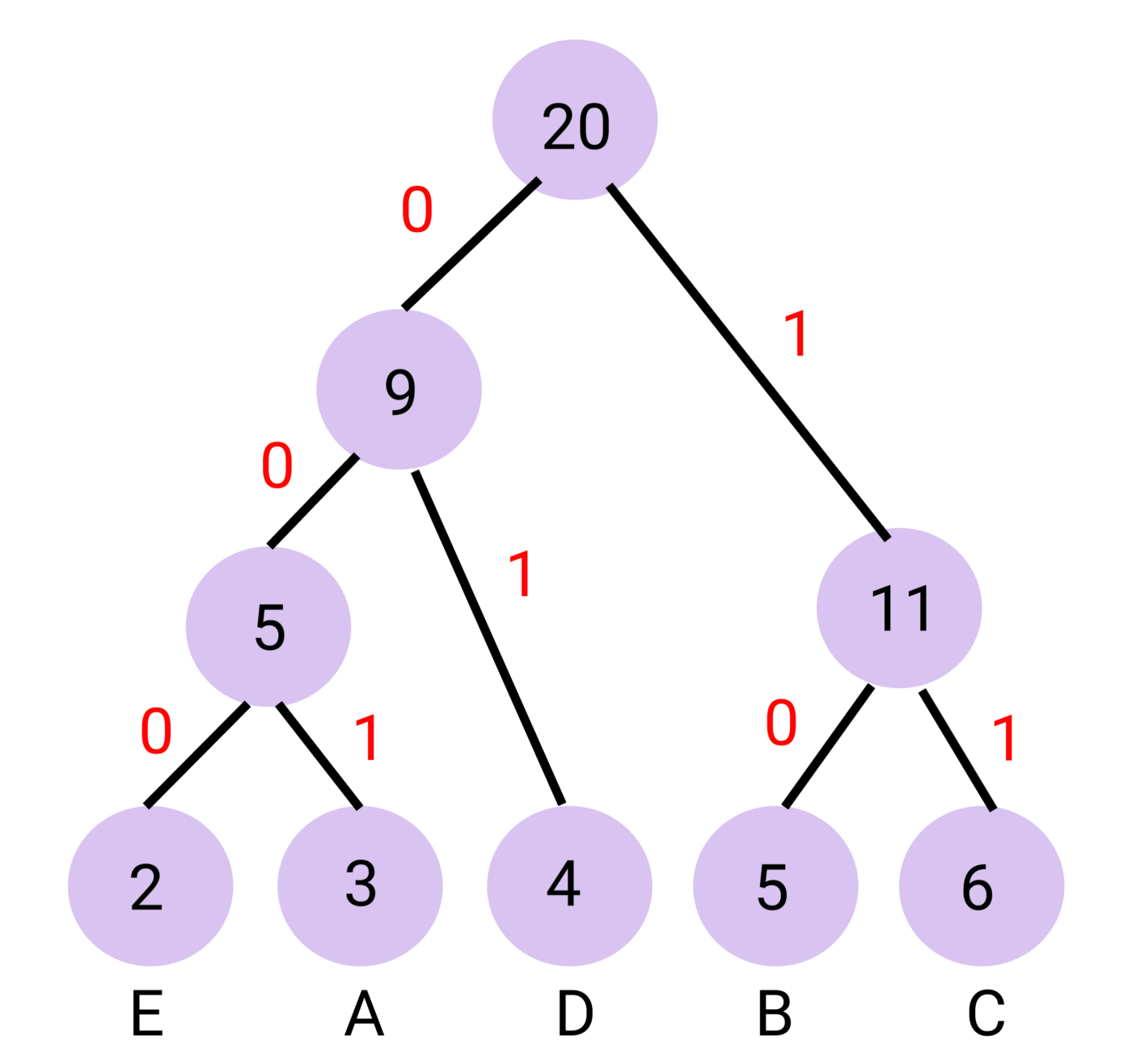
Huffman Coding works by creating a binary tree, a tree data structure with only one or two paths. Want to encode a character? Traverse the tree and take note of the left and right turns you make before you reach a character, this ‘binary’ path is the characters Huffman Code.
Decoding is just as simple. Start at the root node and iterate over a stream of bits. Take the left path at a zero, and the right path at a one. Once you reach a ’leaf node’, a node with no children, you know that you have decoded a character and can move back to the root node for decoding further bits by traversal.
With this tree structure, decoding and encoding is simple!
Wanna create a Huffman Tree? Follow these steps.
- Figure out the frequency of all the characters in a string, discard characters that do not occur in the string.
- Create a ’leaf node’ for every used character.
- Get two nodes with the smallest frequency
- Create a new node with it’s frequency set to the sum of both of it’s child node
- Repeat steps 3 and 4 until there is only one node left that has not been consumed, this is the root node of the binary tree.
But hold on, where do we store these nodes in a way that extracting a node always returns the smallest one? Is this even possible to do efficiently? Enter, the min heap …
You Are Entering The Min Heap
The min heap is a special data structure, and yes, it has nothing to do with heap memory. It is a structure that you can insert data into, and it will automatically arrange itself in a way that the first element in the heap is the smallest one. It’s quite efficent too, not relying on naive loop iterations to find the smallest element.
It’s a form of binary tree but a little unconventional. It does not employ a pointer to get to it’s children, instead it uses an array index to determine it’s nodes. Take a look at these points.
- The first array index contains the root
- The next two elements of the array contain the root’s children
- The next four elements contain the four children of the root’s two child nodes
- And so on …
typedef struct {
size_t len;
size_t cap;
int *data;
} MinHeap;
int node_i;
int child_1 = 2 * node_i + 1;
int child_2 = 2 * node_i + 2;
How do you balance the heap so that the smallest element is always at the front?
Heapify
The heapify function is a recursive one. It starts by first doing comparisons on it’s children to figure out what to swap, then if the index was swapped with it’s children, swap the two nodes and recurse deeper into the min heap. Trust me, I did not understand this on the first go, I still have trouble getting my head around it. It’s okay though, it doesn’t get much harder than this.
void heapify(MinHeap *h, int i)
{
int smallest = i;
int leftChild = 2 * i + 1;
int rightChild = leftChild + 1;
if (leftChild < h->len && h->data[leftChild] < h->data[smallest])
smallest = leftChild;
if (rightChild < h->len && h->data[rightChild] < h->data[smallest])
smallest = rightChild;
if (smallest != i)
{
// swap
int tmp = h->data[i];
h->data[i] = h->data[smallest];
h->data[smallest] = tmp;
heapify(h, smallest);
}
}
For pushing and popping from the min heap, I use these functions.
void heap_push(MinHeap *h, int a)
{
heap_grow(h, 1); // ensure capacity for element
int i = h->len - 1;
// reorder heap and find a place for the element
while (i != 0 && a < h->data[(i - 1) / 2])
{
h->data[i] = h->data[(i - 1) / 2];
i = (i - 1) / 2;
}
h->data[i] = a;
}
int heap_pop(MinHeap *h)
{
int tmp = h->data[0];
h->data[0] = h->data[h->len - 1];
h->len--;
// rebalance heap, recurse the tree
heapify(h, 0);
return tmp;
}
To recap, a min heap is an array data structure with it’s first element always being the smallest. Internally a min heap uses a binary tree based on element indexes and uses a heapify function to rebalance the heap when needed.
Okay, I think I can move onto Huffman Coding now!
As a refresh, here are the steps again, this function below will execute all of this.
typedef struct HuffmanNode HuffmanNode;
struct HuffmanNode {
size_t weight;
uint8_t ch;
HuffmanNode *left, *right;
};
- Figure out the frequency of all the characters in a string, discard characters that do not occur in the string.
- Create a ’leaf node’ for every used character.
- Get two nodes with the smallest frequency
- Create a new node with it’s frequency set to the sum of both of it’s child node
- Repeat steps 3 and 4 until there is only one node left that has not been consumed, this is the root node of the binary tree.
#define BYTE_RANGE 256
HuffmanNode *huffman_rank(string b){
size_t chars[BYTE_RANGE] = {0};
// characters in C are just bytes, it's easy to
// allocate a throwaway table on the stack to
// keep track of 0 - 255 entries.
// all values in the array are initialised to zero
// with the `= {0};`
uint8_t *p = b.cstr;
size_t pos = b.len;
// len can never be zero, is checked when read
while (pos--) chars[*p++]++;
// pretty obfuscated C one liner, just loops through
// every entry in the string and indexes into an array
// using it's byte value. the value stored in the
// array is each character's weight/frequency.
MinHeap h = new_heap(50); // preallocate space for 50 nodes
// create leaf nodes for every used character
for (int i = 0; i < BYTE_RANGE; i++)
{
if (chars[i]){ // if char_weight != 0
// new_huffman_node consumes the character
// and it's weight
heap_push(&h, new_huffman_node(i, chars[i]));
}
}
// consume nodes from the heap until there is one left
while(h.len != 1) {
heap_push(&h, join_huffman_node(heap_pop(&h), heap_pop(&h)));
}
HuffmanNode *root = heap_pop(&h); // this is the root node!
free(h.data); // heap is not needed anymore
return root;
}
Well, we have a tree, time to create the Huffman Codes!
You need to traverse every branch of the tree and take note of the left and right turns you make before you reach a character and assign it’s ‘binary’ path to a map that we can reference later.
HuffmanNode *root = huffman_rank(file);
HuffmanMapEntry map[256];
walk_huffman(map, root, 0, 0);
typedef struct {
uint16_t data;
uint8_t len;
} HuffmanMapEntry;
// 256, 128, 64, 32, 16, 8, 4, 2, 1
// 9 possible left or right branches
// from the avaliable 256 characters,
// store the bits in a u16.
void walk_huffman(HuffmanMapEntry map[],
HuffmanNode *root,
uint16_t data,
uint8_t len)
{
// take the left path, data is already zeroed,
// no point writing a 0 to a bit that is already 0
if (root->left) {
walk_huffman(map, root->left, data, len + 1);
}
// take the right path, write a 1 to the bit place
// at the current depth
if (root->right) {
data |= 1 << len;
walk_huffman(map, root->right, data, len + 1);
}
// reached a leaf node! record it's huffman code
// and the length/depth
if (!(root->left) && !(root->right)) {
map[root->ch].data = data;
map[root->ch].len = len;
}
}
Time for the next step. We have all the huffman codes corresponding to used characters in a text, time to encode them!
This is where I needed something new, a buffer that I can write single bits to. Bits not bytes, that’s the hard part.
The BitArray
typedef struct {
size_t bitlen;
// bits written, not bytes
size_t idx; // current byte index
size_t cap; // capacity in bytes
uint8_t *data;
} BitArray;
typedef _Bool Bit;
Remember the first paragraph, the rant? This is where the bug popped up, and it was a nasty one.
You see, memory allocated with malloc is not initialised. The kernel just hands you back reused memory as it sees fit. Although uninitialised values means it could be anything, usually memory from malloc is mostly zeros. This is in contrast to memory statically allocated, through a global variable and such. Those blocks of memory are almost always filled with junk.
You see this line? It just means, if the bit ‘w’ is one, write that bit to the current place in the bit array. The bit array keeps an internal ‘bitlen’, that contains how many bits have been pushed to the array.
if (w) b->data[b->idx] |= 1 << ( b->bitlen % 8 );
You can assume from the line that values allocated in the array buffer are zero initialised. I mean, why wouldn’t them be? Spoiler alert, I had no idea that background memory corruption was taking place.
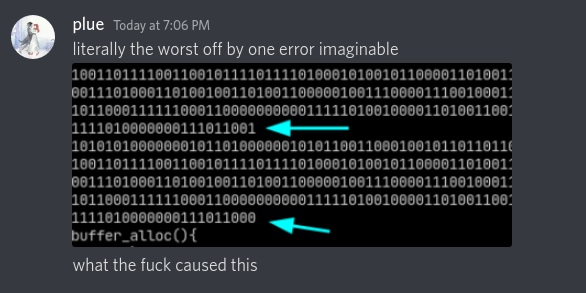
And yes after initialising my array, it went away. I am pretty pissed to have wasted 2 days over a pretty dumb mistake, i’m better than that. Anyway, here is the function to write a single bit to a bit array.
void bitarray_write(BitArray *b, Bit w){
if (w) b->data[b->idx] |= 1 << ( b->bitlen % 8 );
// write a single bit to it's place in the array
b->bitlen++;
// if length has crossed over a byte boundary
if (b->bitlen && b->bitlen % 8 == 0) {
// go to the next byte to start writing bits
b->idx++;
// handle array reallocation
if (b->idx >= b->cap) {
b->cap *= 2;
b->data = realloc(b->data, b->cap);
}
// initialise the value to zero...
b->data[b->idx] = 0;
}
}
Encoding The File
Since we know the Huffman Codes of every character and a bit array to write to, it’s time to finally encode the file using their Huffman Code. I’ll give a recap below.
void encode_huffman(HuffmanMapEntry map[], Buffer file, BitArray *b){
for (size_t i = 0; i < file.len; i++)
{
HuffmanMapEntry m = map[file.data[i]];
uint8_t mask = 0;
while (m.len--)
bitarray_write(b, m.data & 1 << mask++);
}
}
HuffmanNode *root = huffman_rank(file);
HuffmanMapEntry map[256];
walk_huffman(map, root, 0, 0);
BitArray b = bitarray_new(50);
encode_huffman(map, file, &b);
bitarray_print(&b);
- Generate a Huffman Tree by ranking all characters weights in a string or file
- Create a map/lookup table of all characters to store their Huffman Code for encoding
- Walk to all branches of the Huffman Tree, visiting all leaf nodes containing the characters. Write the their Huffman Code into the map.
- Create a new bit array to write out the compressed/encoded file.
- Iterate through every character in the string/file and match it to their Huffman Code in the map. Write their Huffman Code out into the bit array.
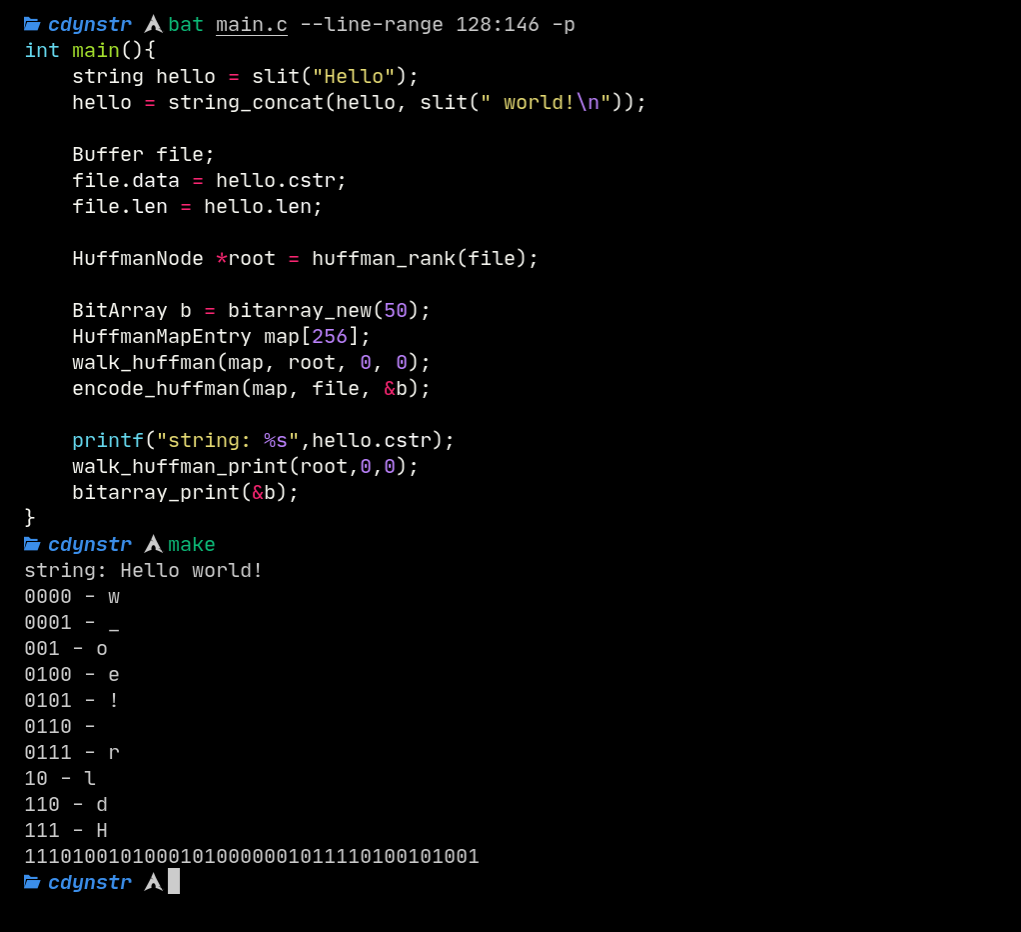
The End?
I really urge you to check out the repository, it contains code for writing the encoded data into a file and decode it right back out. It also contains complete self contained code for all of the data structures and designs I used in this post. C files and headers both come to be easiliy read over and, with some editing, be used in your own projects! Here are the 5 collections of code ontop of the base Huffman Coding project:
- Iteration over single bits
- Small bit array
- Dynamic strings example
- Min heap
- Relative pointers
Catch the source code here!
https://github.com/l1mey112/huffman-dynstr-c https://git.l-m.dev/l-m/huffman-dynstr-c