Learning By Doing In C Part 3 - A Web Server with HTTP 1.0 Using Sockets
Intro
HTTP is an amazing protocol, it has to be.
Thanks to international standardisation, open standards power a free web where just the implementation of a standard like HTTP allows an introduction to an entire ecosystem where each client can understand and share with eachother.
These standards, or rules, outline exactly how something should work. How to implement certain features, how you to handle different situations and what is allowed and what is not. Without an international standard like HTTP, no one would know how to interact with eachother on the web at all.
For example, Unix based systems like GNU/Linux and BSD mostly comply with POSIX, a family of standards for maintaining compatibility between operating systems. With POSIX, a standard for a C Library often called ’libc’ was mandated. With ’libc’, I can be pretty confident that a binary compiled on a Linux distribution would run on a completely different Operating System, assuming it is compliant to POSIX and contains an up to date C library.
Free software and open standards propel innovation.
The HTTP 1.0 standard
Well what is it?
HTTP stands for Hypertext Transfer Protocol. It’s a network protocol used to provide basically all files and data on the World Wide Web.
Usually, HTTP takes place through TCP/IP sockets.
A modern browser is essentially just a HTTP client alongside renderers for certain content like HTML. It sends requests to an HTTP Web server, which then sends responses back. The standard port for HTTP is 80, though any port can be used.
HTTP works as a single response matching a single request. It doesn’t maintain any kind of open connection information like Websockets. After delivering a response, the server closes the connection.
The format for a HTTP request is very simple and human readable.
A request line has three components, separated by spaces. A method name, the requested path and the version of the HTTP standard being used. The most widely used method is ‘GET’, which just means ‘I want this resource’. There are other methods, like ‘POST’, but my webserver will only support ‘GET’ as it only serves static resources.
GET / HTTP/1.1
GET /data/image.png HTTP/1.1
After this initial line, headers can be included alongside the request. Some examples of headers are supplied below.
Host: example.l-m.dev
Connection: keep-alive
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:104.0) Gecko/20100101 Firefox/104.0
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Cookie: lastConnection=1662225450528; GeoIP=AU:xx:xx
Cookies are just strings stored in your browser, passed to websites in a HTTP/HTTPS request header when needed. There are also headers like the user agent, used to identify your browser.
My webserver only parses the top line in requests and all passed headers are ignored.
A response line is quite similar as it also has three sections separated by spaces. It includes the HTTP standard’s version, a response status code and some words in English describing the status code. An example would be the 404 error code, meaning that the requested resource was not found.
HTTP/1.0 200 OK
HTTP/1.0 404 Not Found
HTTP/1.0 500 Internal Server Error
In a response and requests, the message body is placed after the initial line and headers. The body can be anything, human readable text and html or even a pure binary stream for images and applications.
In the HTTP standard it communicates the usage of CRLF line endings. What are these?
It’s an abbreviation that refers to Carriage Return and Line Feed. CR and LF are special characters that are used to sigify where a new line begins.
If you are on Windows, you already use them when typing everything. On everything else, a simple Line Feed or backslash ‘N’ in C is used instead. A backslash ‘R’ in C is used to denote a Line Feed also.
const char *intial_line = "HTTP/1.0 200 OK\r\n\r\n";
const char *server_header = "Server: Simple-C-Server\r\n";
const char *mimetype_header = "Content-Type: text/html\r\n";
const char *body_divider = "\r\n";
This request line would …
GET /index.html HTTP/1.1
… facilitate this response:
HTTP/1.0 200 OK
Server: Simple-C-Server
Content-Type: text/html
<!DOCTYPE html>
<html>
<head>
<title>Welcome!</ti....
.......................
.......................
An initial line with a line space underneath, some headers and then a final line space for the response body storing the requested content.
After a line space after the headers, you have free reign to use whatever line endings you want. You are not bounded by the HTTP standard anymore and can include whatever you want regarding the contents of the requested file. It doesn’t even need to be plaintext, a binary stream from a file is acceptable also.
So you know now that a HTTP response is just plaintext information placed at the top, with the requested file’s content placed at the bottom. I can now get on with sockets, the technology with roots dating back to the early internet.
TCP Sockets
Network Sockets serve as an endpoint for sending and receiving data across a network. The term dates back to 1971 when it was first used in the ARPANET, the first wide-area packet-switched network and one of the first networks to implement the TCP/IP protocol. The technologies that ARPANET helped pioneer became the foundation of the Internet as we know today.
Most implementations of Network Sockets today are based on ‘Berkeley sockets’ originating in 1983 from the BSD Operating System.
Any application can communicate with a socket with TCP/IP by knowing the protocol type, an IP address and a port number. At the time of creation, a network socket is bound to the network address of the host, and a port number.
To create a port in C contains slightly more boilerplate than higher level languages, but allows for more lower level control.
A Very Simple Web Server
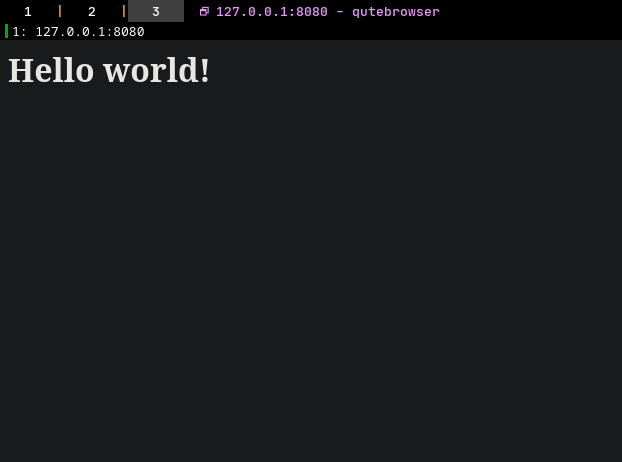
This is the smallest amount of code required to:
- Bind and listen on a port
- Await any kind of connections
- Read and print the request
- Reply with the HTTP initial line and some HTML data
- Close the connection and await more
It isn’t even entirely compatible to the HTTP standard, as it misses out on headers that are required. That’s okay though, because modern browsers give you a lot of leeway. It also does not check if the request conforms to the HTTP standard or if it is even a HTTP request. It only accepts connections and replies back. Take a look below …
#include <sys/socket.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
const char *initial_line = "HTTP/1.0 200 OK\r\n\r\n";
const char *response = "<h1>Hello world!</h1>";
int main()
{
int port = 8080;
uint32_t bind_addr = INADDR_LOOPBACK;
// INADDR_LOOPBACK is just the loopback address, 'localhost'
// INADDR_ANY would be 0.0.0.0, exposing it to the outside
// http://127.0.0.1:8080/
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
// Open a socket as a file descriptor
struct sockaddr_in server_address;
// Struct to store the server address and bind port for the socket
server_address.sin_family = AF_INET; // IP protocall family
server_address.sin_port = htons(port); // Port number
server_address.sin_addr.s_addr = htonl(bind_addr); // Bind address
struct sockaddr *bindptr = (struct sockaddr *)&server_address;
if (
bind(server_fd, bindptr, sizeof(server_address)) < 0 ||
listen(server_fd, 10) < 0
) abort();
// Bind socket using struct information and start listening, abort on fail
// Buffer stores entire request data, GET requests are rarely this big
char buf[1024];
// Start event loop
// Wait for a new connection on the socket and return it's file descriptor
for(;;) {
int client = accept(server_fd, NULL, NULL);
// Read from the client into the buffer and print the request
size_t sz = recv(client, buf, 1024, 0);
fwrite(buf, 1, sz, stdout);
// Send the initial line and the html data to satisfy the GET request
send(client, initial_line, strlen(initial_line), 0);
send(client, response, strlen(response), 0);
// Close the connection with the client
close(client);
}
}
Keep in mind this code will only work on systems conforming to POSIX. No Windows sorry! This code should compile and run on Linux or BSD systems perfectly. It would even run fine on a macOS as it is entirely compatible with POSIX, underneath the hood macOS employs the BSD Kernel.
If you do run one of these systems, try it out! It has been tested to run on all popular C compilers (gcc, clang and tcc).
It is located at ’examples/example-tiny-server.c’ in the projects root directory, Github/Gitea link at the bottom of the post.
Serving Static Content
The code above is easily extendable to support a lot more features. The final version of my web server is able to serve static data, cache content and execute C functions on custom routes.
First, it would need to parse a request. Requests contain the request type (GET, POST, …) and the location requested separated by spaces.
I created a new function in my C string library for exactly that.
#include "strings.h"
int main(){
string hello = slit("31/08/2022");
printf("%s\n", string_pop_delimit(&hello, slit("/")).cstr );
printf("%s\n", string_pop_delimit(&hello, slit("/")).cstr );
printf("%s\n", hello.cstr);
}
// gcc -I. examples/example-delimit.c strings.c && ./a.out
// 31
// 08
// 2022
It works by editing the current string passed in and splits it by a delimiter. Running the function multiple times with the same argument will ‘pop’ parts of the string on the left side of the delimiter off.
What if the delimiter is not present? It would result in an error and the function will return a string with zero length and a NULL data pointer. This has to be checked for to ensure that the request is a HTTP one.
char buf[1024];
size_t sz = recv(conn, buf, 1024, 0); // receive data from the client
string request = string_from_buf(buf, sz);
string req_type = string_pop_delimit(&request, slit(" "));
if (string_is_strerr(req_type) || !string_equals(req_type, slit("GET"))) {
server_warn(server, "Request is not GET");
SEND_400; // 400 Bad Request
goto EXIT;
}
string loc = string_pop_delimit(&request, slit(" "));
if (string_is_strerr(req_type)) {
server_warn(server, "Malformed request");
SEND_400; // 400 Bad Request
goto EXIT;
}
// "GET / HTTP/1.1" -> req_type: "GET", loc: "/"
// "GET /data/image.png HTTP/1.1" -> req_type: "GET", loc: "/data/image.png"
If the request isn’t a GET request or does not contain a proper path, it fails and returns a 400 error code. The 400 error code means a bad request and some HTML information will be sent back to indicate such to the user.
With the location requested in a string, we can search for a resource on the server to send back.
// typedef struct {
// string path;
// char *data;
// int64_t len;
// } CachedFile;
CachedFile *file = NULL;
string file_path = server->webroot;
// The server webroot is essentially the base directory on which static
// content will be served from. Like the "www" folder on certain webservers.
if (string_equals(loc, slit("/"))) {
file_path = join_path(file_path, slit("/index.html"));
// Serve "webroot/index.html" if the "/" route is requested
} else {
if (loc.cstr[0] != '/') {
server_warn(server, "Malformed location request");
SEND_404;
goto EXIT;
}
// Serve "webroot/requested_http_path"
file_path = join_path(file_path, loc);
}
// Read and cache file requested
file = server_get_file(server, file_path);
// If the file could not be found, return a 404
if (file == NULL){
server_warn(server, "Could not find file %s",file_path.cstr);
SEND_404;
goto EXIT;
}
// Found file and is ready to be served
server_info(server, "Requested '%s', serving '%s'", loc.cstr, file_path.cstr);
The file and server headers can then be sent.
send(conn, headers.data, headers.len, 0);
send(conn, file->data, file->len, 0);
close(conn);
server_info(server, "Connection closed");
Serving static content really is that simple!
Just parse the location on a request, join it with the path of the static content folder, read the file and if it was found, send it back to the user!
I said that read files were cached, I’ll explain that now.
The server contains a field that stores a buffer of files …
#define CACHE_RING_BUFFER_LEN 4
struct Server {
// ....
// ....
// ....
CachedFile cache[CACHE_RING_BUFFER_LEN];
// ....
}
… stored in what is called a ring buffer.
+-----+-----+-----+-----+
| 5 | 6 | _ | _ | <- buffer of
+-----+-----+-----+-----+ size 4
^
───────────────┘
+-----+-----+-----+-----+
| 5 | 6 | 3 | _ | <- reached
+-----+-----+-----+-----+ the top
^
─────────────────────┘
+-----+-----+-----+-----+
| 5 | 6 | 3 | 9 | <- and loops
+-----+-----+-----+-----+ around.
^
───┘
+-----+-----+-----+-----+
| 7 | 6 | 3 | 9 | <- overwrites
+-----+-----+-----+-----+ older data
^
─────────┘
A ring buffer (or circular buffer) is a data structure that uses a single, fixed-size buffer as if it were connected end-to-end.
My implementation of a ring buffer allows for the oldest cached file to be overwritten by a newer one.
Ring buffers aren’t exactly ring shaped as computer memory is quite linear, the wrapping implementation is done with a modulus.
// ring buffer wrap
cache_position++;
cache_position %= CACHE_RING_BUFFER_LEN;
When reading a file, if it doesn’t exist in the cache ring buffer, insert it into the buffer and return it. If it does exist, don’t bother reading, just return the file in memory.
The Event Loop
My webserver spawns new threads to handle every new request.
In a loop, it waits till a new connection is accepted and gets it’s file descriptor. Since functions on threads created with the pthread C library can only have 1 argument, a void pointer, memory is allocated to store a struct containing the rest of the arguments.
A thread is then created, passed the function and the argument struct, and detached from the ‘server_run’ function.
void dispatch(dispatch_args *args);
// Will execute and respond to requests
void server_run(Server *server) {
for(;;) {
int client_sock_fd = accept(server->sock_fd, NULL, NULL);
// Accept a connection and return a client file descriptor
dispatch_args *args = malloc(sizeof(dispatch_args));
// Allocate memory for function arguments, threads can
// only accept a void pointer and no other arguments.
args->server = server;
args->client_sock_fd = client_sock_fd;
args->tid = 0; // To be written into
// Copy data into arguments
pthread_create(&args->tid, NULL, (void*)dispatch, args);
pthread_detach(args->tid);
// Create a new thread to handle the request and detach it
// Detaching a thread means it will handle returning itself
}
}
int main() {
Server s = server_create(8080, INADDR_LOOPBACK);
// Create a server on the loopback addres with port 8080
// http://127.0.0.1:8080/
server_serve_content(&s,"www/");
server_run(&s);
// server_run() will never return
}
Doing it in this way allows for requests to not block other requests from being handled. Webservers do this to allow an extreme amount of throughput (that the CPU can handle). The ‘dispatch()’ function then does the request parsing and file reading to return a response.
What if you want to not be bounded by static files? To build up your own response by running arbitrary C code on any routes you specify?
This is where custom routes come in.
Custom Routes
You can assign custom routes to callback functions.
server_assign_route(&s, "/counter", route_counter);
All callback functions must accept the current server context and two string builders containing headers for the response and the response itself. It also must return a boolean controler whenther the request failed or not. If the request failed it will return a 500 error code (Internal Server Error).
All custom routes are always checked for first, then static files.
bool cb_func(Server *server, str_builder *resp, str_builder *headers);
Here is an example of a custom route. It stores a counter as a global variable and increments it. Based on the number stored in the counter it returns a different response.
int counter = 0;
bool route_counter(Server *server, str_builder *resp, str_builder *headers)
{
builder_append_cstr(headers, "Content-Type: text/plain\r\n");
if (counter == 17171717) {
// 500 Internal Server Error
return false;
}
builder_printf(resp, "counter = %d\n\n", counter);
if (counter % 2 == 0) {
builder_append_cstr(resp, "counter is even\n");
} else {
builder_append_cstr(resp, "counter is odd\n");
}
counter++;
// 200 OK
return true;
}
“Multipurpose Internet Mail Extensions”
Mimetypes, you’ve probably seen them before.
.mp4 -> video/mp4
.css -> text/css
.gif -> image/gif
.html -> text/html
.js -> text/javascript
.png -> image/png
Placed inside a “Content-Type” header, it communicates to the browser what type of content is being received for it to then determine how to display it. Just like in Unix based systems (GNU/Linux, macOS), the file extension usually doesn’t mean much. The browser relies on the MimeType sent inside the HTTP header rather than the file extension.
Luckily, we just need to match the file extension on served static files to a list of hardcoded MimeTypes in our code.
const string mimetypes[] = {
slit(".txt"), slit("text/plain"),
slit(".ttf"), slit("font/ttf"),
slit(".aac"), slit("audio/aac"),
slit(".css"), slit("text/css"),
slit(".csv"), slit("text/csv"),
slit(".gif"), slit("image/gif"),
slit(".htm"), slit("text/html"),
slit(".html"), slit("text/html"),
slit(".jpeg"), slit("image/jpeg"),
slit(".jpg"), slit("image/jpeg"),
slit(".mid"), slit("audio/midi"),
slit(".midi"), slit("audio/midi"),
slit(".mp2"), slit("audio/mpeg"),
slit(".mp3"), slit("audio/mpeg"),
slit(".mp4"), slit("video/mp4"),
slit(".mpa"), slit("video/mpeg"),
slit(".mpe"), sli ................
..................................
..................................
This function will take a file path, match it’s file extension and return the correct MimeType.
string match_file_type(string path){
int last_dot = -1;
for (int i = 0; i < path.len; i++)
{
if (path.cstr[i] == '.') last_dot = i;
}
if (last_dot == -1)
return strerr; // no file extension
// path/file.tar.gz
// |
// last_dot
string path_ext = string_substr(path, last_dot, path.len);
// path_ext = '.gz'
if (path_ext.len == 1) // if == '.'
return strerr;
// loop over mimetype pairs and return the correct one
for (int i = 0; i < mimetypes_len; i += 2)
{
if (string_equals(path_ext,mimetypes[i])) {
return mimetypes[i+1];
}
}
return strerr;
}
builder_printf(&headers, "Content-Type: %s\r\n", mimetype.cstr);
If the file does not contain a file extension or it’s extension does not appear on the list, a NULL string will be returned. This will be checked for and the MimeType sniffing will be employed to find a suitible type.
While the name might put you off, it just means that the content of the file will be inspected to determine the MimeType instead of the file extension. Usually browsers implement a more advanced version, mine simply checks the first 50 bytes for printable ASCII characters.
string mimetype = match_file_type(file_path);
if (string_is_strerr(mimetype))
{
mimetype = slit("text/plain");
// Search the first 50 chars for non printable characters
for (int i = 0; i < MIN(50, file->len); i++) {
if ( !( isprint(file->data[i]) || isspace(file->data[i]) ) ){
mimetype = slit("application/octet-stream");
break;
}
}
}
ISALPHA(3) Linux Programmer's Manual ISALPHA(3)
DESCRIPTION
isprint()
checks for any printable character including space.
isspace()
checks for white-space characters. In the "C" and
"POSIX" locales, these are: space, form-feed ('\f'), new‐
line ('\n'), carriage return ('\r'), horizontal tab
('\t'), and vertical tab ('\v').
The default MimeType for files without extensions is ’text/plain’. The file is then read and checked for printable characters, if there is a single non printable characters the MimeType is ‘application/octet-stream’. It is the default type for all binary data.
It’s over
Thanks for checking in to this post! Learning how to use POSIX Sockets and the basics of HTTP was pretty thought provoking. I am really enjoying this series so far and I definitely want to make more.
As always the code is hosted on Github and Gitea along with some examples at the root of the project.
Goodbye!