Release Changelog - stas 0.1.1
No intro today, I am throwing you right in.
Visual Studio Code Extension Support
This, this was needed. I learn regex and programming in stas gets easier? That’s a win win.
Some knowledge of regex is required to write a syntax highlighing extension for VScode. Besides that, it was a breeze. I just followed this-official-guide for that.
Honestly, I’ve never used regex properly until now. I went to regexlearn to give it a try and that was all I needed. You won’t get much out of the tutorial however, it’s a lot to take in. I still recommend completing it, then moving onto the cheatsheet, it’s a lifesaver.
stas is far from a complicated language and it is parsed in a very simple way. All characters have the ability to be a word or identifier. Identifiers are used in stas to give names to variables and functions. Instead of a variables name being restricted to alphanumeric characters, stas allows you to use literally anything besides a whitespace character.
This poses a problem.
The while keyword, on it’s own, will be parsed as such. The stas scanner will iterate over all whitespace till it comes across one that is not, it will then switch into a different mode and keep iterating over all characters until it encounters a whitespace, it then knows the start and end of a word and will begin to check if it is a keyword or not else, it is an identifier.
This regex line will locate all characters inbetween a ‘word boundary.’ Usually whitespace, but this includes other characters like periods. This is what we don’t want.
/\b(if|else|elif|while|break|continue|ret)\b/
Want to fix it? Instead of a using word boundary, you must create your own boundary guard. Negative Lookbehind and Negative Lookahead groups can be used to ensure whitespace on either side. If in doubt, reference the cheat sheet.
"patterns": [
{
"name": "keyword.control.stas",
- "match": "\\b(if|else|elif|while|break|continue|ret)\\b"
+ "match": "(?<!\\S)(if|else|elif|while|break|continue|ret)(?!\\S)"
},


These match groups prepended and appended to a regex line are used a ton over the entire syntax specification. Perfect!
What is most important to me, is that syntax highlighting should accurately represent what the compiler would see. It must emulate it perfectly, as syntax highlighting gives very useful visual cues to the programmer.
"repository": {
"comments": {
"name": "comment.line.stas",
"begin": "(?<!\\S);",
"end": "$"
},
"numbers": {
"name": "constant.numeric.integer.stas",
"match": "(?<!\\S)\\-?(\\d+)(?!\\S)"
},
"scopeName": "source.stas"
stas Compiler CLI Improvements
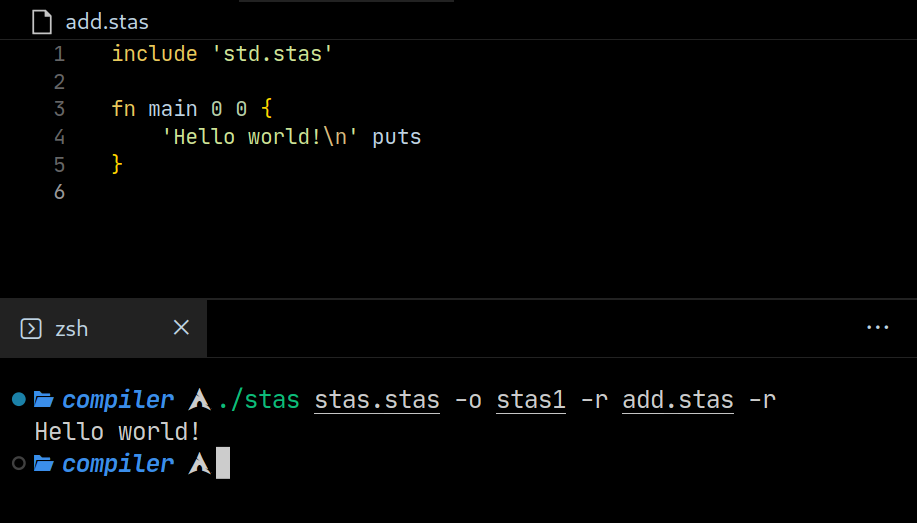
- Use the ‘-r’ switch to execute the file after compilation, arguments after this switch will ignored and passed to the program.
- Stack backtraces showing exactly what value was pushed onto the stack and where on a compiler error.
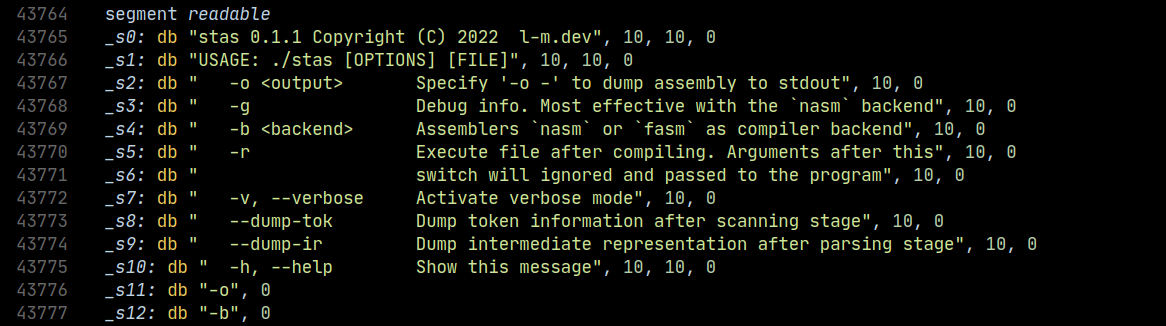
- ‘–dump-tok’ and ‘–dump-ir’ switches for dumping the compiler’s inner data structures.
- ‘-v’ or ‘–verbose’ enables verbose mode. Compiler passes will be timed and lots of information will be dumped.
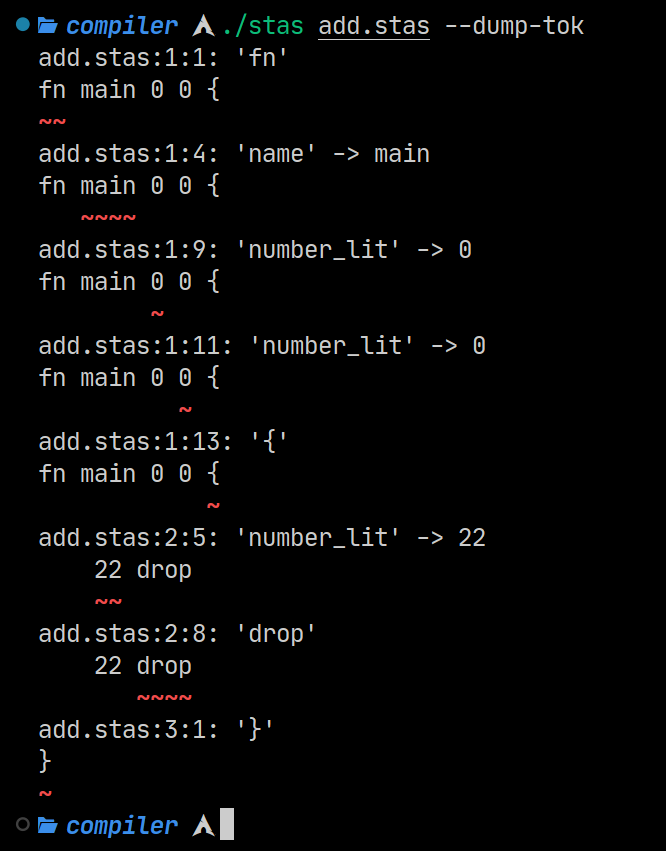
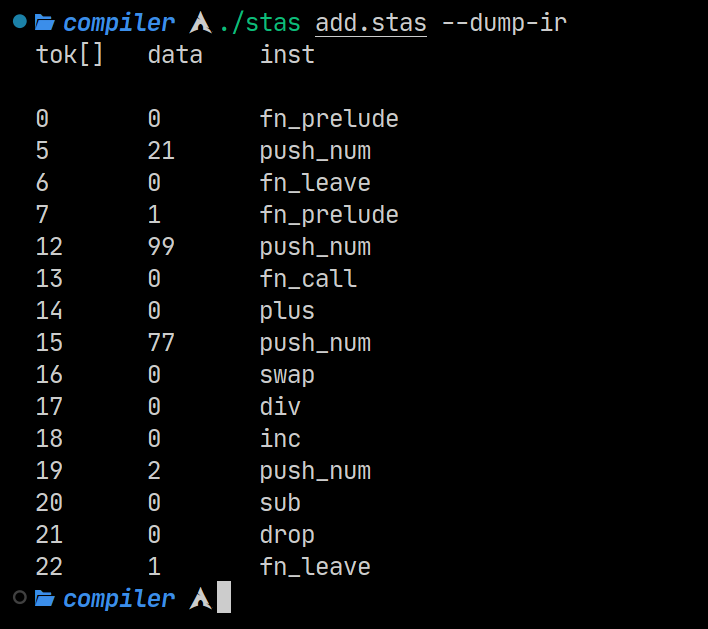
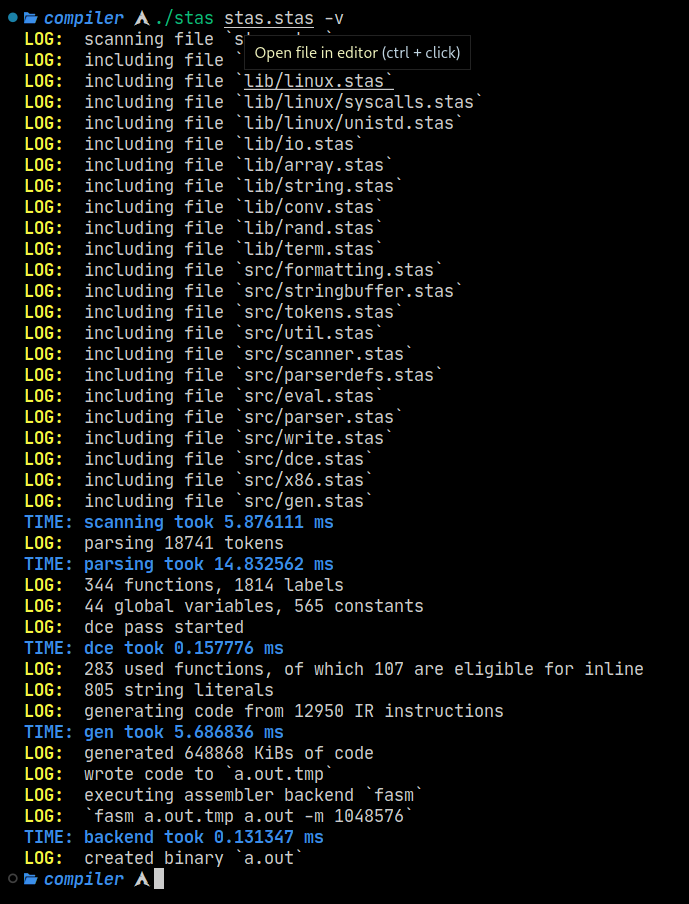
A very very nice addition is the ability to execute a file after compilation and pass arguments straight to it.
./stas stas.stas -o stas1 -r add.stas -r
This command uses the stas compiler to compile a new compiler with the name ‘stas1,’ then execute that compiler with the arguments ‘add.stas -r’. This will cause the new compiler to compile and execute the ‘add.stas’ file.
Being able to compile a new compiler, then use that compiler in a split second is what makes stas easy to iterate on and improve!
Single Character Literals
- Single character literals denoted with backticks.
I stole this syntax from V. Character literals are a must for reducing random magic numbers in source code.
All a character literal bakes down to is a number anyway…
$ ./stas1 add.stas --dump-tok
add.stas:2:2: 'string_lit' -> "sello"
+ 'sello'
- ~~~~~~~
add.stas:3:2: 'number_lit' -> 115
+ `s`
- ~~~
add.stas:5:2: 'number_lit' -> 10
+ `\n`
- ~~~~
`\n` eputc
while dup 0 > {
pos -- pop pos
10 %%
`0` +
pos swap w8
len ++ pop len
}
drop
Vastly Improved Code Generation
- Pretty printing of string literals in generated assembly.
include 'std.stas'
fn main 0 0 {
"Hello!\n" puts
}
./stas add.stas -o - | bat -lnasm
If you peek into the assembly output, you will notice that string literals are now human readable strings instead of an array of integers.
You may think this change would force string literals to use a lot more space, but you would be wrong.
segment readable
_s0: db 72, 101, 108, 108, 111, 33, 10, 0
segment readable
_s0: db "Hello!", 10, 0
- Code generation when inlining function bodies has been improved greatly.
- Bugfix: consecutive inline functions with branches no longer have their labels conflict.
Functions stas have their operands passed through the stack, but keep a register to register context in it’s body. If you inline a function, you would never want to leave the register based context right? It would be pointless to push all of those arguments and pop them off after an inline. Anyway, when inlining a function their arguments are never issued through the stack, instead inheriting the current register context from the parent fuction.
- r_flush
fn_c rFunction.forbid_inline ! if {
; inline the function
} else {
+ r_flush
; call the function
}
include 'std.stas'
fn main 0 0 {
"Hello!\n" puts
}
const stdout { 1 }
const sys_write { 1 }
; (stream str len -- count)
fn write 3 1 {
sys_write syscall3
}
; (str len)
fn puts 2 0 {
stdout rot write drop
}
fn main 0 0 {
"Hello!\n" puts
}
On a high level, the function ‘puts’ is implemented with a second function. They are both recursively inlined when invoked.
Stack shuffling operators, such as ‘rot’, to rotate 3 values on the stack and ‘swap’, to swap 2 values, are essentially a no-op when done register to register.
When using the stack however, such as whenever a function used to be called regardless of it’s inline status, they are quite expensive and result in an a lot of useless operations.
To show this, I compiled two versions of the stas compiler. One where the register ‘stack’ is flushed on a function call, regardless if it is inlined or not, and one where the stack based calling convention is only used when it is applicable, when a non inline function is called. The code blocks highlighted are the instructions resulting from calling the ‘puts’ function and it’s interal inlined calls.
It’s a major difference.
| |
| |
- Tail recursion optimisation.
int fib_tail(int n, int a, int b)
{
if (n == 0)
return a;
if (n == 1)
return b;
return fib_tail(n - 1, b, a + b);
}
int fib(int n)
{
fib_tail(n, 0, 1)
}
(define (factorial n)
(if (= n 1)
1
(* n (factorial (- n 1) ))
))
Have you seen this kind of code before? Where a recursive function call is placed at the end of the body?
This distinguishes the function as ’tail recursive.'
What does this mean to the compiler? The compiler can trivialy optimise the call away. Really!
When the parser identifies a self call, it allocates a label and keeps it for later. The parser is not the one who identifies if the call is tail recursive, a second pass, the DCE or dead code elimination pass is awarded that job.
When the DCE pass comes across a self call, it determines if it is in the tail end by going IR instruction by instruction following branches in the IR down to the the functions end. If it came across anything other than a branch or a label, there is more code ahead of the function call, therefore it is not placed in the tail end.
However, if it is in the tail end, the call IR instruction is replaced with an unconditional jump to the label set aside by the parser.
fn decrease 1 1 {
dup 0 != if {
-- decrease
}
}
fn main 0 0 {
22 decrease drop
}
See, no call instruction!
| |
| |
The ‘addr’ Keyword
- New ‘addr’ keyword. Used to get addresses of variables declared with the ‘auto’ keyword.
Before this change, buffers created with the ‘reserve’ keyword were always pointers to a block of memory. Automatic variables are simply ‘automatic,’ this means automatic dereferecing, easy allocation and simple syntax to deal with writing.
Just specifying the variable name is enough, it is now on the stack. This can also be done by taking the address of the variable and dereferecing it manually.
fn main 0 0 {
auto my_var 1
my_var ; (my_var)
}
fn main 0 0 {
auto my_var 1
addr my_var ; (*my_var)
r64 ; (my_var)
}
Counterproductive, but this is just an example, it has it’s place.
One example where they are useful, is when selecting different parts of an automatic variable. A string literal contains two parts, the length and a char pointer. An automatic variable of length 2 is used often to contain them both, but until now it was impossible to access these fields.
I plan for a special syntax to ‘select’ these fields safely.
fn main 0 0 {
auto string 2
"hello!" pop string
addr string
r64 ; (string.len)
addr string
8 + r64 ; (string.data)
}
Improved Interactions With Early Returns
- Unreachable code declared after the use of the ‘ret’ keyword is now checked for and is a compiler error.
- Bugfix: stack checks on branches with early returns with the ‘ret’ keyword are no longer implemented with a nasty hack.
| |
$ ./stas add.stas
add.stas:11:9: unreachable code
The NASM Backend And Debug Information
- NASM backend, generates object files and annotated assembly with exported labels with the ‘-g’ switch.
The debug switch ‘-g’ does a lot of things depending on what assembler backend you are using.
Lets take the decrease function from earlier and make it a little segfaulty.
fn segfaulter 1 1 {
dup 0 != if {
-- segfaulter
}
r64
}
fn main 0 0 {
555 segfaulter drop
}
$ ./stas add.stas -o a.out # implicit `-b fasm`
$ gdb a.out --silent
(gdb) run
Program received signal SIGSEGV, Segmentation fault.
0x0000000000400158 in ?? () # WHERE AM I???
(gdb) bt
0 0x0000000000400158 in ?? ()
1 0x0000000000000001 in ?? ()
2 0x00007fffffffe091 in ?? ()
3 0x0000000000000000 in ?? ()
(gdb)
GDB won’t tell us where we are. It’s simple to tell why, FASM is called the ‘flat assembler.’ It creates flat binaries, smallest possible. That means no public labels, address information, backtraces, all of it.
However I know for sure GDB cannot get good backtraces because it is not aware of the second stack used to store return addresses and local variables. It assumes some values on that stack are return addresses. Anyway…
The default backend is FASM, unless specified otherwise with the ‘-b’ switch. It creates executable binaries super quick without any debugging information. Compiling with the ‘-g’ switch will activate debug mode. It will create backend specific code to mark all function labels and display other information. It will also always generate an object file. In the future, the linker will be called inside the compiler automatically.
$ ./stas add.stas -o a.o -g
$ ld a.o -o a.out
$ gdb a.out --silent
(gdb) run
Program received signal SIGSEGV, Segmentation fault.
0x0000000000401070 in segfaulter ()
(gdb)
This also works flawlessly with the new NASM backend.
Bug got introduced into the compiler? Don’t know where?
$ ./stas stas.stas -o stas1
$ ./stas1 add.stas
[1] 602887 segmentation fault (core dumped) ./stas1 add.stas
The debug mode will tell you exactly where it is.
$ ./stas stas.stas -g -b nasm -o stas1.o
$ ld stas1.o -o stas1
$ gdb --silent --args ./stas1 add.stas
(gdb) run
Program received signal SIGSEGV, Segmentation fault.
0x0000000000422624 in label.def.fwriteln ()
(gdb)
New examples
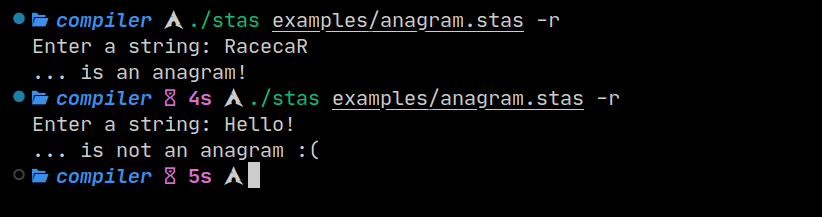
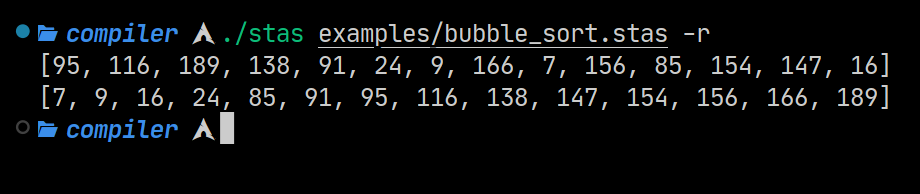
There isn’t much to say here…
Closing Up
Told you I was quick.
Expect some kind of guide, very very soon. Just when the stas compiler does not use hardcoded executable paths. It is not recommended that you build stas and experiment with it in this state. Expect that to be cleaned up soon.
Goodbye, I’ve got some decently big plans for the next release.