Release Changelog - stas 0.1.2
Portable To All Linux Distributions.
- New ’envp’ keyword for accessing environment variables. A ‘getenv’ function is provided.
- Now portable to all Linux distributions due to proper PATH enviroment variable being parsed and read.
A new keyword has been added to access the enviroment pointer, just like in C. The ’envp’ keyword pushes a pointer to an array of nul terminated strings onto the stack. It contains all of the enviroment variables passed to the program on It’s creation.
The ‘PATH’ variable specifies the directories in which executable programs are located on the computer. It saves you from typing out the entire path when invoking a program.
Not all Linux distributions have the exact same directory layout, paths to key executables used in stas have been hardcoded before this release. Now using the ‘getenv’ function from the standard library to get the ‘PATH’ enviroment variable, it can be searched through to locate the actual executables path.
include 'std.stas'
fn main 0 0 {
"fasm" find_abs_path_of_executable?
; (str? len)
over NULL != assert
-> 'executable not found'
; (str len)
puts endl
}
So go ahead, try stas!
$ fasm -m 1048576 bootstrap/x86-64_linux.fasm stas
$ ./stas
stas 0.1.1 Copyright (C) 2022 l-m.dev
USAGE: ./stas [OPTIONS] [FILE]
-o <output> Specify '-o -' to dump assembly to stdout
-g Debug info. Most effective with the `nasm` backend
-b <backend> Assemblers `nasm` or `fasm` as compiler backend
-r Execute file after compiling. Arguments after this
switch will ignored and passed to the program
-v, --verbose Activate verbose mode
--dump-tok Dump token information after scanning stage
--dump-ir Dump intermediate representation after parsing stage
-h, --help Show this message
Short Form Function Declarations.
- Short form function declarations for functions that accept and return zero values.
fn main 0 0 {
;
}
fn main {
;
}
The syntax for a function signature was made specifically simple to aid in parsing. I’ve always felt the extra zeros to specify a void function was pointless. This was quite straightforward to add.
Duplicate String Literals.
- Attempts to merge duplicate string literals. Similar to ‘-fmerge-constants’ in GCC.
Thought it was a pretty good thing to add, see this code.
fn main {
"Hello!" drop drop
"Hello!" drop drop
"Cello!" drop drop
"Hello!" drop drop
"Cello!" drop drop
}
String literals are now merged after the sight that many duplicate string literals were present in the source code of the compiler.
It runs inside the DCE pass, where string literals are resolved.
After compiling the compiler, 4KiBs of junk strings were removed, not bad.
main:
mov [_rs_p], rsp
mov rsp, rbp
mov rbx, _s0
mov rsi, 6
mov rbx, _s0
mov rsi, 6
mov rbx, _s1
mov rsi, 6
mov rbx, _s0
mov rsi, 6
mov rbx, _s1
mov rsi, 6
mov rbp, rsp
mov rsp, [_rs_p]
ret
segment readable
_s0: db "Hello!", 0
_s1: db "Cello!", 0
Rich Error System.
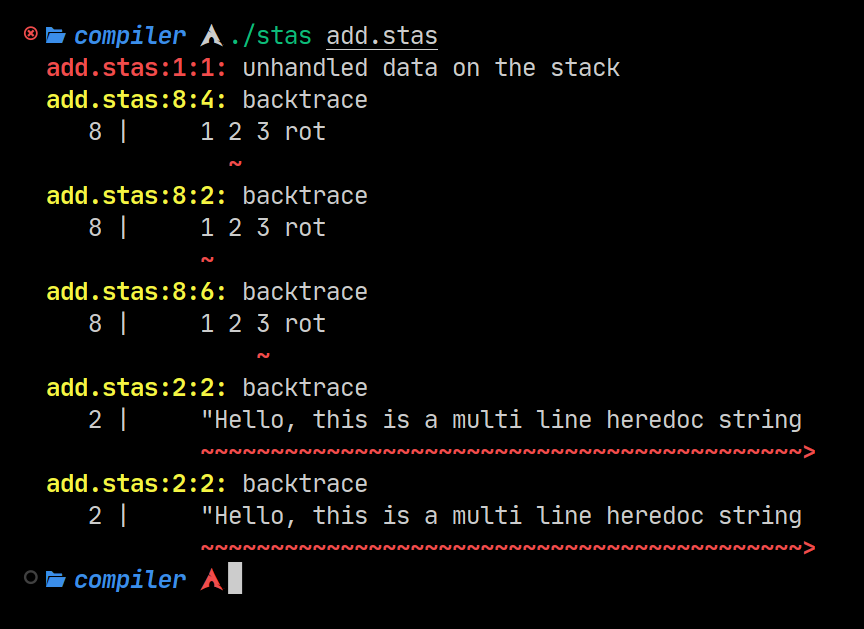
- Rich error system showing and underlining the exact token inside the file that caused the error.
- Bugfix: scanner fixes for multi line character and string literals.
- Bugfix: stack shuffling operations now return correct backtraces in a parser error.
This used to be in the original version of stas. Shortened now to only show one highlighted line, but underlines the offending token in It’s entirety. Changes had to be made to the inner token representation to allow a field that stored It’s length.
| |
| |
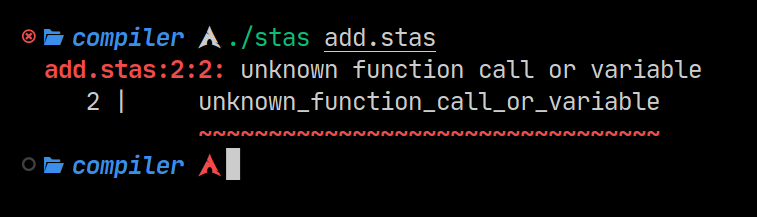
Good error reporting in a compiler is very important. It’s extremely useful and allows stas to get right to the point when conveying errors to the programmer.
Seamless Linker Usage
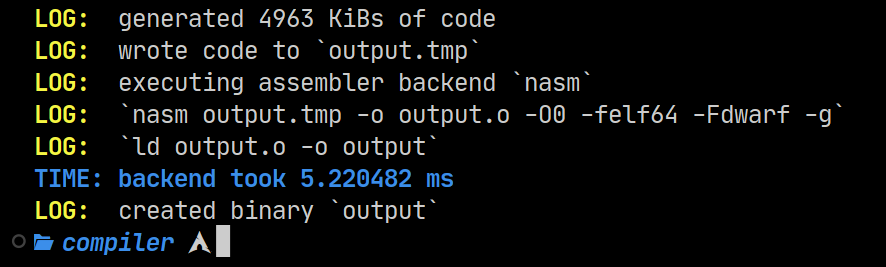
- The linker is now called when generating object files.
When using debug symbols or the NASM backend, the old behavior simply outputted an object file and exits. People will assume that the output of the compiler will be an executable, especially if the output name is set using the ‘-o’ switch.
This is all handled automatically. See this command:
$ ./stas add.stas -b nasm -g -v -o output
Function Attributes.
- Function attributes. ’noreturn’, ‘inline’ and ’noinline’ are supported.
Function attributes are super useful. I use a similar syntax and style to V.
They give extra hints to the stas compiler on certain functions.
- noinline
fn my_noinline_functor {
2 drop
}
fn main {
my_noinline_functor
}
This function is tiny, and will automatically be inlined.
main:
mov [_rs_p], rsp
mov rsp, rbp
mov rbx, 2
mov rbp, rsp
mov rsp, [_rs_p]
ret
The ’noinline’ attribute will guarantee the function will never be inlined.
my_noinline_functor:
mov [_rs_p], rsp
mov rsp, rbp
mov rbx, 2
mov rbp, rsp
mov rsp, [_rs_p]
ret
main:
mov [_rs_p], rsp
mov rsp, rbp
mov rbp, rsp
mov rsp, [_rs_p]
call my_noinline_functor
mov [_rs_p], rsp
mov rsp, rbp
mov rbp, rsp
mov rsp, [_rs_p]
ret
The function below is too large to be inlined…
- inline
fn my_forced_inline {
2 drop
2 drop
2 drop
2 drop
2 drop
2 drop
2 drop
2 drop
2 drop
}
fn main {
my_forced_inline
}
The ‘inline’ attribute will guarantee the function will always be inlined.
main:
mov [_rs_p], rsp
mov rsp, rbp
mov rbx, 2
mov rbx, 2
mov rbx, 2
mov rbx, 2
mov rbx, 2
mov rbx, 2
mov rbx, 2
mov rbx, 2
mov rbx, 2
mov rbp, rsp
mov rsp, [_rs_p]
ret
Guarentee is the keyword here. If for any reason it cannot, it will throw a compilation error.

- noreturn
fn exit 0 0 {
}
fn main {
exit
2 3 1
}
The ’noreturn’ attribute will mark a function that it will never return, either by terminating the process or resulting in an infinite loop.
It is UB to return from a function marked as noreturn, as calling it causes some side effects and assumptions inside the parser.
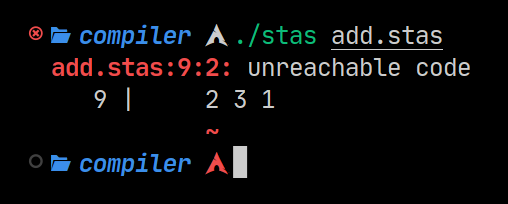
Calling a noreturn function, similar to an early return from a function, will push an unreachable scope onto the parsers stack. It will call an ‘unreachable code’ error if any other code is found after it.
Overflow Checks.
- Overflow checks for signed and unsigned integers.
; ( is_negative str len -- bool )
fn does_int_literal_overflow 3 1 {
auto lit 2 pop lit
if {
"9223372036854775808"
} else {
"18446744073709551615"
}
......
......
......
fn main {
18446744073709551616 drop
}
fn main {
-9223372036854775809 drop
}
The scanner now checks for overflowed integer literals, signed or unsigned.
Not much to be said here.
Minor Bugfixes That Make A Major Difference.
- Bugfix: fix early return scopes that caused errors with complex blocks.
- Bugfix: add error for unhandled scope that a complex block requires.
- Bugfix: if and else cases with an early return now are checked correctly in the parser.
These bugfixes fix a ton of bugs relating to parsing branching scopes. Some fix errors with the stack checks done inside the parser and others handling early returns in branches. Good fixes overall.
End.
Time to write some guides.
Goodbye.