The V WebAssembly Compiler Backend, Rewritten
“wasm: webassembly backend rewrite #18120”
This PR contains updates on the progress of the ongoing WebAssembly (WASM) backend rewrite for the V programming language.
..
The original WASM backend had convoluted code for memory access and local stack variables, which led to a rewrite. The new backend is being developed alongside the
wasmmodule and will no longer depend on the Binaryen toolchain, except for production builds (which an externalwasm-optwill be needed)...
The backend will support all previous V features, alongside options and a limited implementation of result types, with a new built-in module closer to expectations.
..
There are many issues relating to building the WASM backend on other platforms, due to it’s dependency on Binaryen. An outdated version of
stdc++is common on some Debian and Ubuntu operating systems.
Okay, the backend needed to be rewritten. A dependency on the Binaryen toolchain was nice, supporting easy serialisation and optimisation passes present inside the library, however it’s downsides were greater than the upsides.
Binaryen wasn’t the best because it was very hard to package, depenency management is a pain, and shipping the library out to users who expect a simple git clone and run for the V compiler was not ideal. There were scripts present to automatically download the library, however even then getting it working on some platforms was a challenge.
So, to ditch Binaryen. What does Binaryen do that we can do ourselves?
For one, a nice API for WebAssembly code generation. If I can do that in pure V, then we can remove Binaryen.
import wasm
all programming languages should include a code generator in it’s standard library. this is my take.
——— me.l-m.dev
The ability to generate code is a very powerful tool. Exposing it to userspace through the standard library so users can interact with it is a must. My thoughts were, if I am going to do all of this work to implement a library to generate WebAssembly code, why not make it generic? No point in walling it off for compiler use only.
import os
import wasm
fn main() {
mut m := wasm.Module{}
mut f := m.new_function(
'fac', [.i64_t], [.i64_t])
{
f.local_get(0)
f.eqz(.i64_t)
label := f.c_if([], [.i64_t])
{
f.i64_const(1)
}
f.c_else(label)
{
{
f.local_get(0)
}
{
f.local_get(0)
f.i64_const(1)
f.sub(.i64_t)
f.call('fac')
}
f.mul(.i64_t)
}
f.c_end(label)
}
m.commit(f, true) // export: true
buf := m.compile()
os.write_file_array('mod.wasm', buf)!
}Trust me, it’s fast. As fast as appending bytes to a buffer can be.
The code to the left is a simple example of how the library works.
The interface takes a different turn, instead of generating Binaryen AST nodes using their custom IR, the library generates WebAssembly bytecode directly.
This is much simpler, and much closer to how WebAssembly is actually represented.
00021 func[0] <fac>:
000022: 20 00 | local.get 0
000024: 50 | i64.eqz
000025: 04 7e | if i64
000027: 42 01 | i64.const 1
000029: 05 | else
00002a: 20 00 | local.get 0
00002c: 20 00 | local.get 0
00002e: 42 01 | i64.const 1
000030: 7d | i64.sub
000031: 10 00 | call 0 <fac>
000033: 7e | i64.mul
000034: 0b | end
000035: 0b | end$ v run codegen.v
$ wasmer mod.wasm -i fac 3
6
$ wasmer mod.wasm -i fac 6
720
$ wasmer mod.wasm -i fac 10
3628800It handles everything inside the current WebAssembly specification.
This includes sign extension operations, non trapping conversions, multiple values, and bulk memory instructions. What isn’t present is vector instructions, and proper support for tables and reference types.
Even just a base implementation, rewriting the compiler saw immediate speed increases for doing the same work.
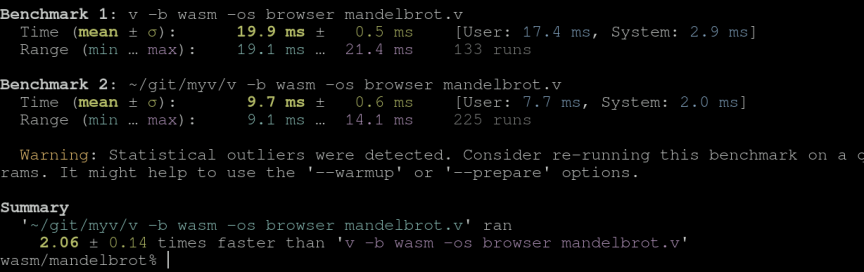
(Re)writing The Backend
fn (mut g Gen) toplevel_stmt(node ast.Stmt) {
match node {
ast.FnDecl {
// function declarations
g.fn_decl(node)
}
/* {...} */
}
}
fn (mut g Gen) toplevel_stmts(stmts []ast.Stmt) {
for stmt in stmts {
g.toplevel_stmt(stmt)
}
}
pub fn gen(files []&ast.File, /* ... */) {
mut g := &Gen{/* ... */}
for file in g.files {
g.toplevel_stmts(file.stmts)
}
}The compiler backend is passed an AST to generate code.
I will not lie, it’s not something I prefer, the AST isn’t usually what you perform code generation on. I learned a lot however, and nearing the end I did not mind.
The way the backend is structured is pretty standard for most other backends. The entry point for the backend, it’s handed a list of files, then traverses them generating code.
I will not explain everything, I already made a guide.
ABI (Application Binary Interface)
An ABI is a set of rules that dictate how functions are called, and how data is passed between functions.
One of the most common ABIs is the C ABI, which is used by most compilers to generate code for C. However, V is much more complex than C. It has multiple return values, error and option types, interfaces, sumtypes, and more. These can’t be represented at all in C, so we need to make our own ABI.
Even though I took a little inspiration from the C ABI, I just rolled my own.
This is the layout I use to generate WebAssembly function signatures from V functions.
parameters: {return structs} (method self) {arguments} -> return: {concrete return}
Accepting and returning concrete types, such as integers, is simple.
fn ret_one(a int, b int) int
fn ret_two(a int, b int) (int, int)WebAssembly supports multi value returns now, so multiple returns are easy to represent.
func $main.ret_one
(param $a<int> i32) (param $b<int> i32)
(result i32)func $main.ret_two
(param $a<int> i32) (param $b<int> i32)
(result i32 i32)What about accepting and returning values that are too large to store in a WebAssembly local, like structs? What about accepting and returning ANY amount of them? This needs to be supported also.
Accepting structs is easy, it’s usually done by
passing a pointer to the structure, and then the
function can read from it. This is what I do. A pointer
is represented as a WebAssembly i32, they
can be easily passed through.
Returning a struct is a little more complex.
The function is passed a pointer to the struct, and it writes to it.
fn ret_struct(a Struct, b Struct) Structfunc $main.ret_struct
(param $__rval<main.Struct> i32)
(param $a<main.Struct> i32)
(param $b<main.Struct> i32)The code generator uses __rval as a
distinction that the parameter is a return value and
not part of the arguments.
Now for a hard one. Accepting a method struct, returning AND accepting multiple concrete types interleaved with a struct. How is this done?
fn (self Struct) run_self(a int, mutator Struct, b i64) (int, Struct, i64)Remember, the ABI specifies that the function signature is layed out with:
parameters: {return structs} (method self) {arguments} -> return: {concrete return}
The backend sorts the parameters into the correct order, and then generates the function signature.
func $main.Struct.run_self
(param $__rval<main.Struct> i32)
(param $self<main.Struct> i32)
(param $a<int> i32)
(param $mutator<main.Struct> i32)
(param $b<i64> i64)
(result i32 i64)It starts processing the return values one by one, putting the struct as a first parameter and leaving the rest beside.
Next is the method self, which is the second parameter. Then last, the rest of the arguments as parameters.
The return values in the multi return that can be represented concretely in WebAssembly can be returned as a value.
WebAssembly is just another ISA, it’s not special. It’s just a little more complex than x86, and a little more portable.
Var{}
And Memory Locations
A memory location is a generic place that can be written to and read from. It’s not necessarily a local, nor a stack slot, it’s just a place that can be written to and read from. This distinction is made so that the backend can abstract over parts of WebAssembly stack machine.
A memory location is represented as such on the right.
Is it a pointer into stack memory? Is it a pointer into the heap? Is it a global? Is it a local? Is it a float value? Is it an integer value?
The backend doesn’t care, it just exposes common operations. Operations such as getting, setting, taking the address of, creating a new memory location offset to another, and more.
struct Var {
name string
mut:
typ ast.Type
// complex flag, is_not_value_type
is_address bool
is_global bool
// wasm.LocalIndex | wasm.GlobalIndex
idx int
// pointer offset
offset int
}
The set() operation is used to generate
code for taking values/pointers already on the
stack, and putting them into locals, or
globals, or stack slots, or heap slots, or
whatever.
fn (Gen) set(v Var)
The get() and ref() kinds
of operations are used to generate code to place a
value onto the stack.
If get()ing a value that is a pointer
into stack memory storing a concrete value type such as
an integer or a float, it will dereference it.
fn (Gen) get(v Var)
fn (Gen) ref(v Var) // &var
fn (Gen) ref_ignore_offset(v Var)
fn (Gen) offset(v Var, typ ast.Type, int) VarVariables can also be offsets to one another, a good example of this is a stack slot offset from the stack pointer.
Instead of generating an entirely new WebAssembly local to store the pointer to that stack slot, the backend can just add that offset to the backing stack pointer.
sp := g.sp() // stack pointer
g.stack_frame += 4
return g.offset(sp, ast.int_type, 0)The ref_ignore_offset() is used take
the address of something without a backing offset, this
can introduce some optimisations when the offset is
known (see below).
The mov() operation is similar to the
x86 “left hand side is destination” instruction. This
is especially useful when and more efficient when the
two memory locations is known, and the backend can make
safe assumptions generating code.
fn (Gen) mov(to Var, v Var)No need to allocate stack memory or make copies, just move from parameter to return value.
The backend sees that the type Struct
is greater than 16 bytes, and so doing a
memcpy would be the fastest.
struct Struct {
buf [128]u8
}
fn mov(param Struct) Struct {
return param // mov(__rval, param)
}Constructing the return value in the return slot is a form of RVO (return value optimisation), and is a common optimisation in compilers.
(func $main.mov
(param $__rval<main.Struct> i32)
(param $param<main.Struct> i32)
(block $label$1
(memory.copy (; memcpy ;)
(local.get $__rval<main.Struct>)
(local.get $param<main.Struct>)
(i32.const 128)
)
(br $label$1)
)
)I open up on the differences between the old variable representation and the new here. It explains why the old version was so bad, and why the new version is way more flexible.
Calling External Functions
This one is simple. The functions from the host are just normal functions, but they have a special prefix.
In the WASI build mode -os wasi the
prefix used is WASM, and functions can be
declared (imported) and called like such.
[wasm_import_namespace: wasi_unstable]
[noreturn]
fn WASM.proc_exit(rval int)
// build with -no-builtin
fn main() {
exit(0)
}(import "wasi_unstable" "proc_exit" (func $wasi_unstable.proc_exit (param i32)))
(func $main.main
(call $wasi_unstable.proc_exit (i32.const 0))
(unreachable) (; marked [noreturn] ;)
)New Features
These were straightforward to implement.
Deferred Statements
Statements are deferred until the end of the
function, not the end of scope. defer {}
was implemented just how the C backend does it.
void main__defer_if(bool cond) {
bool __defer = false;
if (cond) {
__defer = true;
}
println(_SLIT("defer_if: start"));
if (__defer) {
println(_SLIT("defer_if: defer!"));
}
}fn defer_if(cond bool) {
if cond {
defer {
println('defer_if: defer!')
}
}
println('defer_if: start')
}
fn main() {
defer {
println('defer!')
}
println('before defer')
defer_if(false)
defer_if(true)
}__defer flag booleans are set when a
defer block is encountered, and to be read when the
function returns executing the deferred statements.
See the disassembly on the right. It shows the the
__defer flag being set, and then the
deferred code is set at the end.
Optimising WebAssembly JITs would easily be able to optimise this code anyway, since the intent is easily expressible.
0008c7 func[27] <main.defer_if>:
0008d7: 20 00 | local.get 0 <cond<bool>>
0008d9: 04 40 | if
0008db: 41 01 | i32.const 1
0008dd: 21 01 | local.set 1 <__defer>
0008df: 0b | end
| ...
| ... println()
| ...
0008f4: 20 01 | local.get 1 <__defer>
0008f6: 04 40 | if
| ... println()
000915: 0b | endAssertions
They are pretty necessary for debugging, and are a
good way to make sure the code is doing what you expect
it to do. Assertions are stripped on -prod
builds, but serve their purpose in normal
operation.
Assertions can also contain messages, which are string literals. They can’t contain interpolated values.
fn test(cond bool) {
assert cond, 'my response'
}The above code essentially unwraps into below. The
eprintln is used to print a message to
stderr, and the panic is used
to exit the program.
fn test(cond bool) {
if !cond {
eprintln("a.v:2:9: fn main.test: assert cond, 'my response'")
panic('Assertion failed...')
}
}When the compiler hits the assert
statement, the below code is used to generate the
WebAssembly.
It constructs ast.StringLiteral AST
nodes, then calls expr() on them to place
pointers on the stack. It then calls the functions to
pass strings to each.
ast.AssertStmt { // fn (Gen) expr_stmt(ast.Stmt)
if !node.is_used {
return // ignore on -prod builds
}
// calls builtin functions, don't want to corrupt stack frame!
g.is_leaf_function = false
g.expr(node.expr, ast.bool_type) // assert <expr>, ""
g.func.eqz(.i32_t) // !expr
lbl := g.func.c_if([], []) // if !expr {}
{
// fn main.main: ${msg}
// V panic: Assertion failed...
mut msg := '${g.file_pos(node.pos)}: fn ${g.fn_name}: ${ast.Stmt(node)}'
if node.extra is ast.StringLiteral {
msg += ", '${node.extra.val}'"
}
panic_msg := 'Assertion failed...'
// place pointer on stack, then call
g.expr(ast.StringLiteral{ val: msg }, ast.string_type)
g.func.call('eprintln')
g.expr(ast.StringLiteral{ val: panic_msg }, ast.string_type)
g.func.call('panic')
}
g.func.c_end(lbl)
}Bounds Checks
Unlike assertions, these are absolutely neeeded for ensuring program correctness.
A bounds check is performed on every array and string access, and panics if the index is out of bounds.
fn char_at(val string, idx int) u8 {
return val[idx]
}
fn lookup(idx int) int {
a := [20, 25, 30]!
return a[idx]
}fn char_at(val string, idx int) u8 {
__len := val.len
if idx >= __len {
eprintln('a.v:2:12: val[idx]')
panic('index out of range')
}
return val[idx]
}Like assertions, the function char_at
unwraps into such, with the bounds check happening in
an If statement.
A bounds check won’t be performed on functions
tagged [direct_array_access] and where the
bounds check can be statically performed at compile
time.
What about negative indicies? I’ve got that covered too, and for free!
In WebAssembly, the signedness of types is
unspecified. It’s the operations on types that give
them the sign. For example, i32.div_u is
an unsigned division, and i32.div_s is a
signed division.
Performing a “greater than or equal” check where the index is reinterpreted as an unsigned number will force negative numbers to be very large, and will trigger the bounds check.
g.func.ge(.i32_t, false)
// is_signed: false -> i32.ge_u
// negative numbers will be reinterpreted as > 2^31 and will also trigger falseWhat Do We Lose?
Not much, but there are some things that are no longer possible.
The ability to perform optimisation passes provided by Binaryen.
Binaryen has a pretty large suite of in house optimisations that can be called on it’s IR AST.
I’ll be honest, it’s really not needed. Developers really serious about optimising WebAssembly will bring their own tools, such as
wasm-opt. Right now using-prodcallswasm-optexternally. Should save some typing.Pretty printing of the WebAssembly output.
v -b wasm file.v -o -generated a nice output to stdout, similar to how the compiler outputs C code to stdout. This is no longer possible, since the compiler no longer uses Binaryen.It’s been replaced with a pure binary output, which isn’t used for human consumption. Infact, it won’t output unless stdout is piped to a file. That will avoid messing up terminals by writing non UTF-8 binary data.
v -b wasm file.v -o - | wasm-objdump -d -is my current workflow, it’s not nice, but it works.This may be considered in the future, but it’s not a priority.
These things are small, and I think they’re worth the tradeoff of having a portable compiler.
Some WASM Programs
PRNG
WebAssembly supports wrapping two’s complement arithmetic.
It’s even specified in the WASM spec that it assumes a two’s complement enviroment. Assuming this allows for the signedness of types to be non important, allowing for a very compact binary format.
$ ./v -b wasm run a.v
Hello World!
rand: 45
rand: 49
rand: 70
...fn prng(old_state i64) (i64, int) {
state := (old_state * 1103515245 + 12345)
% 2147483647
return state, int(state % 100)
}
fn main() {
println('Hello World!')
mut old_state := i64(0)
for i := 0 ; i < 10 ; i++ {
state, n := prng(old_state)
print('rand: ') println(n)
old_state = state
}
}Mandelbrot
This example was present and able to be compiled in the previous version of the backend, and it still works here.
$ cd examples/wasm/mandelbrot
$ v -b wasm -os browser mandelbrot.v
$ python -m http.server 8080
$ open http://localhost:8080/mandelbrot.htmlCompiling for -os browser allows the
use of imported JavaScript functions.
fn JS.canvas_x() int
fn JS.canvas_y() int
fn JS.setpixel(x int, y int, c f64)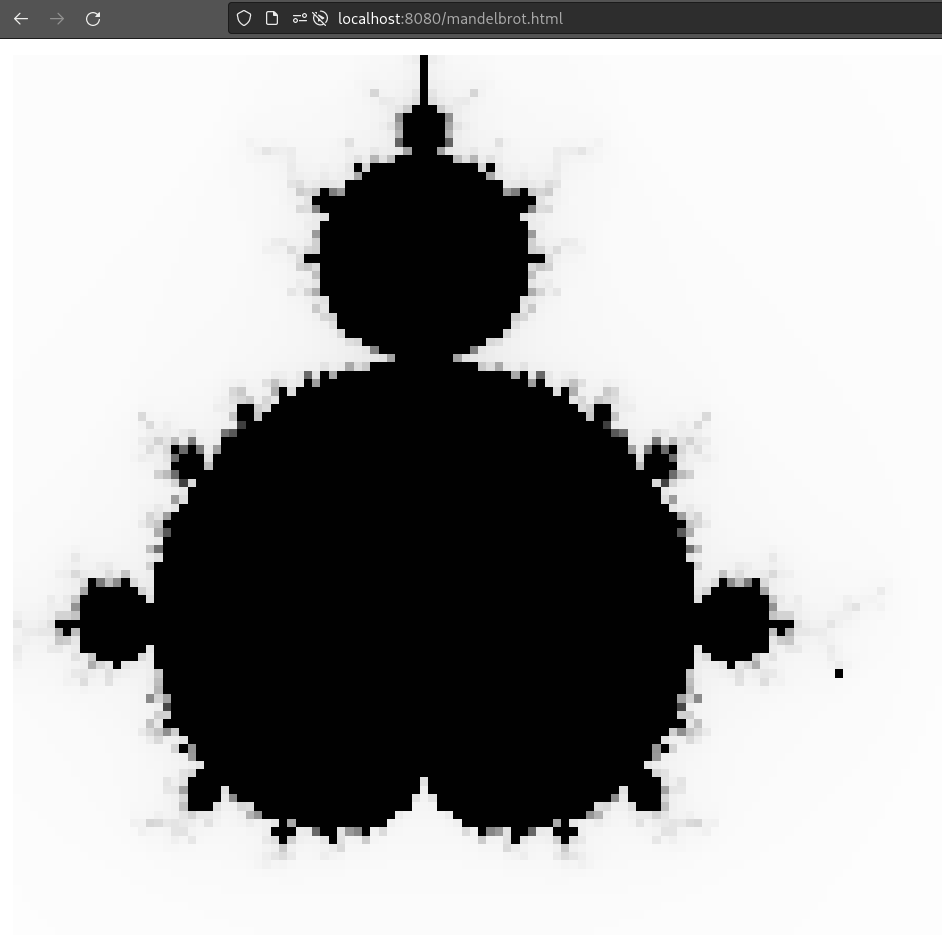
Importing WASI From The Code Generator
Using import wasm, you can generate a
WASI compliant module pretty easily.
This is a very simple example, but it shows how easy it is to import a couple functions and call them.
$ v run file.v
$ wasmer wasi.wasm
$ echo $?
1import wasm
import os
fn main() {
mut m := wasm.Module{}
m.enable_debug('vlang') // module name
// wasi module must export 'memory'
m.assign_memory('memory', true, 1, none)
m.new_function_import('wasi_unstable', 'proc_exit', [.i32_t], [])
// wasi module must contain '_start'
mut func := m.new_function('_start', [], [])
{
func.i32_const(1)
func.call_import('wasi_unstable', 'proc_exit')
}
m.commit(func, true)
os.write_file_array('wasi.wasm', m.compile())!
}The End And The Future
The WebAssembly backend was originally written a while back as a project I took up with very little experience with compilers and code generation. It’s worked out pretty well and I’ve garnered a lot of experience inside the V compiler and as a compiler developer in general.
In the now, the backend is fine as it is.
What I can say for the future is to expect a large change in the compiler infrastructure inside V. The V team is deciding to rewrite a lot of the compiler internals, and that will change how compiler backends are implemented for the better. I’ve been advocating for a concrete AST, proper intermediate representation, and better tooling ever since I started this project alone. I am very glad to be at least partially responsible for this change.
With this change to the compiler internals, proper optimisation, and standardised code generation, I expect V to evolve a whole lot.
I’m very excited for the future of V, and I expect to be there.