I tried x86-64 Assembly
Intro
Till now, I prefered to stay as far away as possible from even touching any kind of assembly. And keep in mind, I’ve written a couple hobby operating systems, all without touching any assembly (thank you Limine bootloader!).
It’s much better when the compiler (foreshadowing) does it all for me. Everything about assembly just turned me off, like:
- The
DWORD PTR [rbp-*]syntax for accessing the stack - All registers are global and there isn’t much of them
- Absolutely no handholding by a compiler. Good luck stepping through each instruction with a debugger!
And last but not least:
- The fact that you have to really think hard about what you were writing
This one was tough, and required reading documentation and inspecting code generated other by compilers to make the right decisions. Compiler Explorer by Matt Godbolt is an amazing tool that really helped me understand the best practices and conventions for good assembly code. His talks at CppCon about low level programming and Compiler Explorer are great!
Assembly Language in 100 Seconds by Fireship is great too, it got me initially interested. It also showed how the Linux kernel processed system calls.
I use NASM, the Netwide Assembler as my main assembler. I’ve tried GAS (GNU assembler) in the past and hated AT&T assembly syntax. Intel syntax just works and is not a pain to read and type (there’s a reason why it’s the default inside Compiler Explorer).
Deconstructing my first program
I’m going to make a lot of comparisons between assembly and the C programming language, I also wont cover everything, just enough.
section .data
string: db "Hello world",10
; 10 is the newline character
global _start
section .text
_start:
call print
exit:
mov rax, 60 ; sys_exit syscall
mov rdi, 1 ; return code of 1
syscall
print:
mov rax, 1 ; sys_write syscall
mov rdi, 1 ; stdout
mov rsi, string
mov rdx, 12 ; length of string
syscall
ret
The data section
There is no variables in assembly, just memory locations/pointers. The data section is where you define chunks of memory to be a known value, to later access this data using a pointer. You see the string: part? Those are called labels, they act effectively like pointers.
NASM has a special syntax to ‘define’ memory.
db "Hello world", 10
db means ‘define byte’, this line defines the bytes for the string “Hello world” and the number 10. The number 10 is just the newline character in ascii, placed at the end of the string, NASM seems to not support escape characters.
Lets see it in action!
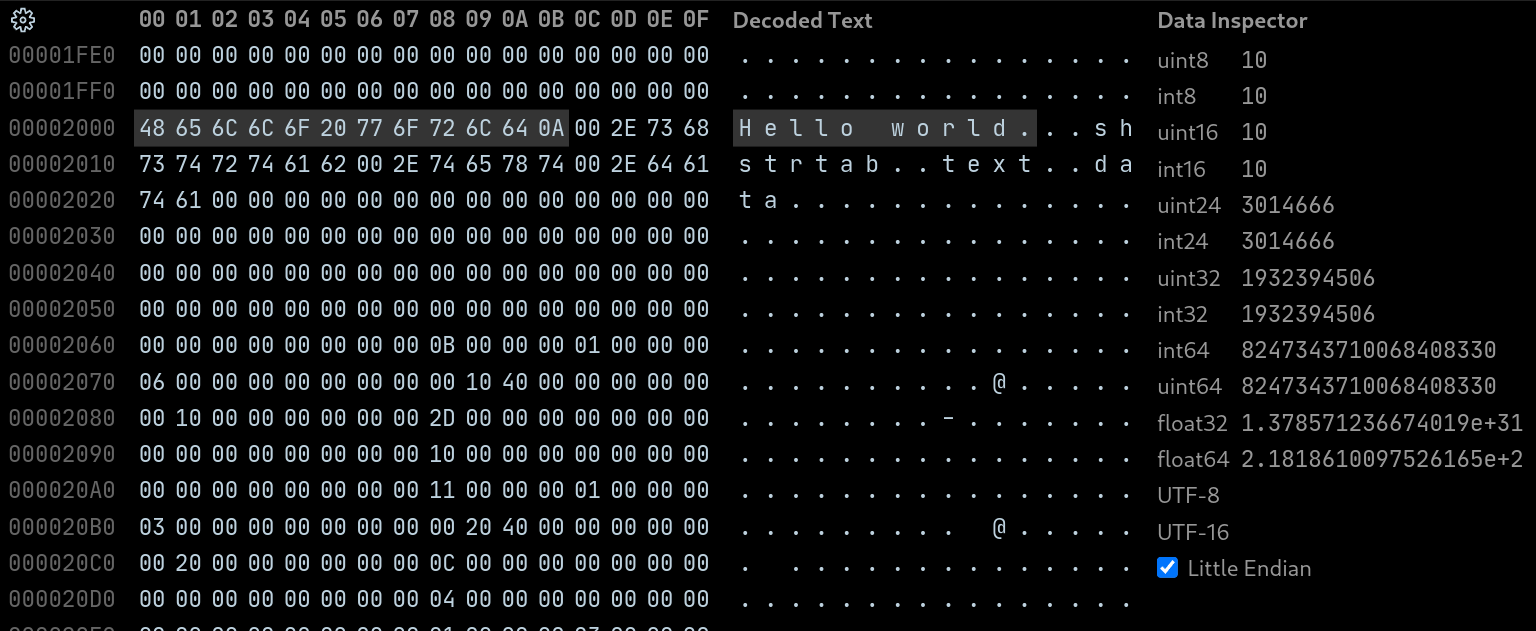
Reading a hexdump of the final executable, after looking around, you can spot the string data nearing the end of the file, the dot highlighted at the end means the byte is not printable, but it still has meaning to us. It’s the newline character we defined earlier and the end of the string.
Take a look at this object dump:
$ objdump -s a.out
a.out: file format elf64-x86-64
Contents of section .text:
401000 e80c0000 00b83c00 0000bf01 0000000f ......<.........
401010 05b80100 0000bf01 00000048 be002040 ...........H.. @
401020 00000000 00ba0c00 00000f05 c3 .............
Contents of section .data:
402000 48656c6c 6f20776f 726c640a Hello world.
You see the memory address 0x402000 that contains our string? Try to spot it below in the dissasembly.
$ objdump -d -M intel a.out
a.out: file format elf64-x86-64
Disassembly of section .text:
...
0000000000401011 <print>:
401011: b8 01 00 00 00 mov eax,0x1
401016: bf 01 00 00 00 mov edi,0x1
40101b: 48 be 00 20 40 00 00 movabs rsi,0x402000 < HERE!
401022: 00 00 00
401025: ba 0c 00 00 00 mov edx,0xc
40102a: 0f 05 syscall
40102c: c3 ret
That line looks pretty similar to:
mov rsi, string
right?
Now you know that the data section can be used to define data and labels can be used as pointers to that data it’s time to move onto the next section.
The blur between data and code
Assembly is as close as you can get to machine code, each statement mostly having an equvalent single machine instruction. Code/Machine instructions are defined inside the text section. Why is code stored in the ’text’ section? I don’t even know why. Maybe it’s because it’s what computers read? Moving on…
All code is data, but not all data is code. What do I mean by this?
You remember in the last section where we could get labels to our data defined inside the data section?
In the ’text’ section, labels are used to define memory locations to parts of machine code. Labels in the text sections are effectively functions when jumped to with the call instruction.
Think of a program as a long tape of instructions, and a pointer that can jump to any part on this hypothetical tape. This pointer starts at the _start: label and marches forward instruction by instruction.
global _start
section .text
_start: <────── Start here!
call print ─────────────────────┐
┌──────> │
│ exit: │
│ mov rax, 60 ; sys_exit syscall │
│ mov rdi, 1 ; return code of 1 │
│ syscall │
│ ; --- terminates here --- │
│ │
│ print: <────────────────────────────┘
│ mov rax, 1 ; sys_write syscall
│ mov rdi, 1 ; stdout
│ mov rsi, string
│ mov rdx, 12 ; length of string
│ syscall
└────── ret
It’s first instruction is call print. The pointer now moves to the memory address at the print label. It goes instruction by instruction, executing each until the ret instruction. The ret instruction returns the pointer to the original call instruction. It now moves to the next instruction, past the exit label. Inserting the correct values in the registers to prepare for an exit system call. It executes the call and the program is terminated there, unable to move to the next instruction. If it was allowed to go past the exit system call it would simply move past the print label and start executing code there!
The pointer in the tape example is the rip register. This register contains the memory address of the next instruction and can be manipulated with function calls, jump instructions and the like. You want your CPU to execute code? Just move it’s ‘instruction pointer’ register to some memory address!
Finally, global _start is to let NASM know that the start label is a global function. A start label is required just like the main function in C is, they serve the same purpose.
That’s it!
Besides the linux system calls, that’s mostly what you would need to know to have a little more than basic understanding of assembly, machine code and executables!
I’ll go a little beyond and deconstruct my second program. A strlen function for null terminated strings. Don’t know what null terminated strings are? Go learn a little C and come right back, please.
The strlen function is essential in C and very much needed for my future programs.
The strlen() function in assembly
I could link with libc, move my arguments in to the correct registers, call strlen from the C standard library and be done with it. But that’s the thing, why taint my perfect statically linked assembly program by linking it with libc? I’ll write my functions by myself.
Calling conventions
How do functions get their arguments? Simple, it’s outlined in a ‘calling convention’
Unix-like operating systems (GNU/Linux, macOS, BSD, etc) use the ‘System V AMD64 ABI’ calling convention. Despite the name, it’s quite simple.
Here’s a table of the registers used when calling a function according to the calling convention.
Register Conventional use Low 32-bits Low 16-bits Low 8-bits
rax Return value eax ax al
rdi 1st argument edi di dil
rsi 2nd argument esi si sil
rdx 3rd argument edx dx dl
rcx 4th argument ecx cx cl
r8 5th argument r8d r8w r8b
r9 6th argument r9d r9w r9b
When returning from a function, the RAX register is always populated with the return value. With this knownledge, you can take apart the final assembly solution!
strlen function
rax Return value | Returns the length of the string
rdi 1st argument | Takes a pointer to a string of characters
strlen:
mov rdx, 0 ; int count = 0;
jmp strloop ; unconditional jump to label
stradd:
add rdx, 1 ; count++
add rdi, 1 ; ptr++
strloop:
cmp byte [rdi], 0 ; does *ptr == 0?
jne stradd ; 'jump if not equal to zero'
; = while (*ptr != 0)
mov rax, rdx ; return count;
ret
; - get length of string in rax
_start:
mov rdi, string_label
call strlen
Try to follow the instruction pointer, start at the entry point and march onwards.
Need help? Here is some perfectly legal but ethically questionable C code that nearly replicates the assembly above:
int strlen(const char * ptr){
strlen:
int count = 0;
goto strloop;
stradd:
count++;
ptr++;
strloop:
if (*ptr != 0) {goto stradd;}
return count;
}
Hope that wasn’t too much! If you got here and really took a good try at understanding everything that layed before you, congratulations!
You have gone a lot farther than 90% of developers.
It’s really a tragedy.
Finishing up
Assembly is great, fun to write even. No one is paying me to say that. Most people shy away from it, but you never really know until you try! I picked up assembly in preparation for a compiler that I am in the middle of drafting out. Writing the builtin functions in assembly bit by bit.
I really advocate for people interested to try assembly. It really makes you think differently, in a good way.
Thank you for reading.